Occurrence of Extreme Observations in Simulated Correlated Null Data
Lei Sun
2016-11-24
Last updated: 2017-12-21
Code version: 6e42447
Introduction
During a conversation with Matthew on correlated \(z\)-scores, Prof. Michael Stein remarked that “if the marginal distribution is correct then the expected number exceeding any threshold should be correct… so if the tail is ‘usually’ deflated, it should be that with some small probability there are many large \(z\)-scores (even in the tail).” So we are running this simulation to check that insight, that is, “if there are usually not enough in the tail then there must be some probability of too many in the tail,” based on the assumption that, on average, the \(p\)-values are uniform after voom transformation.
Using GTex/Liver data, we sample \(N = 10\)K genes from a \(5\) vs \(5\) study, and keep the correlation among genes. The data for each gene can then be transformed by voom to a \(p\)-value; thus we get \(10\)K \(p\)-values for each simulation run. A total of \(m = 1\)K runs generate a \(m \times N\) matrix of \(p\)-values, each row an independent simulation run with \(10\)K genes.
With different pre-specified thresholds \(T_p\), we record, for each of the \(m = 1000\) runs, the number of extreme observations with \(p \leq T_p\). The occurrence table is stored in p_null_liver_extreme.txt.
Result
# load extreme observation count table
p_extreme = read.table("../output/p_null_liver_extreme.txt", header = TRUE, check.names = FALSE)
thresh = as.numeric(names(p_extreme))
m = dim(p_extreme)[1]
J = dim(p_extreme)[2]
N = 1e4
# plot the counts for each threshold
for(j in 1:J) {
pj = p_extreme[, j]
thj = thresh[j]
mean = mean(pj)
sd = sd(pj)
plot(table(pj),
xlab = bquote("no. of obs w/"~p<=.(thj)),
ylab = "frequency",
main = bquote(paste(
"avg" == .(round(mean, 2)),
", sd" == .(round(sd, 1)),
", expected" == .(thj * N)
)
)
)
abline(v = N * thj, col = "red", lty = 3)
legend("topright", "expected", lty = 3, col = "red")
}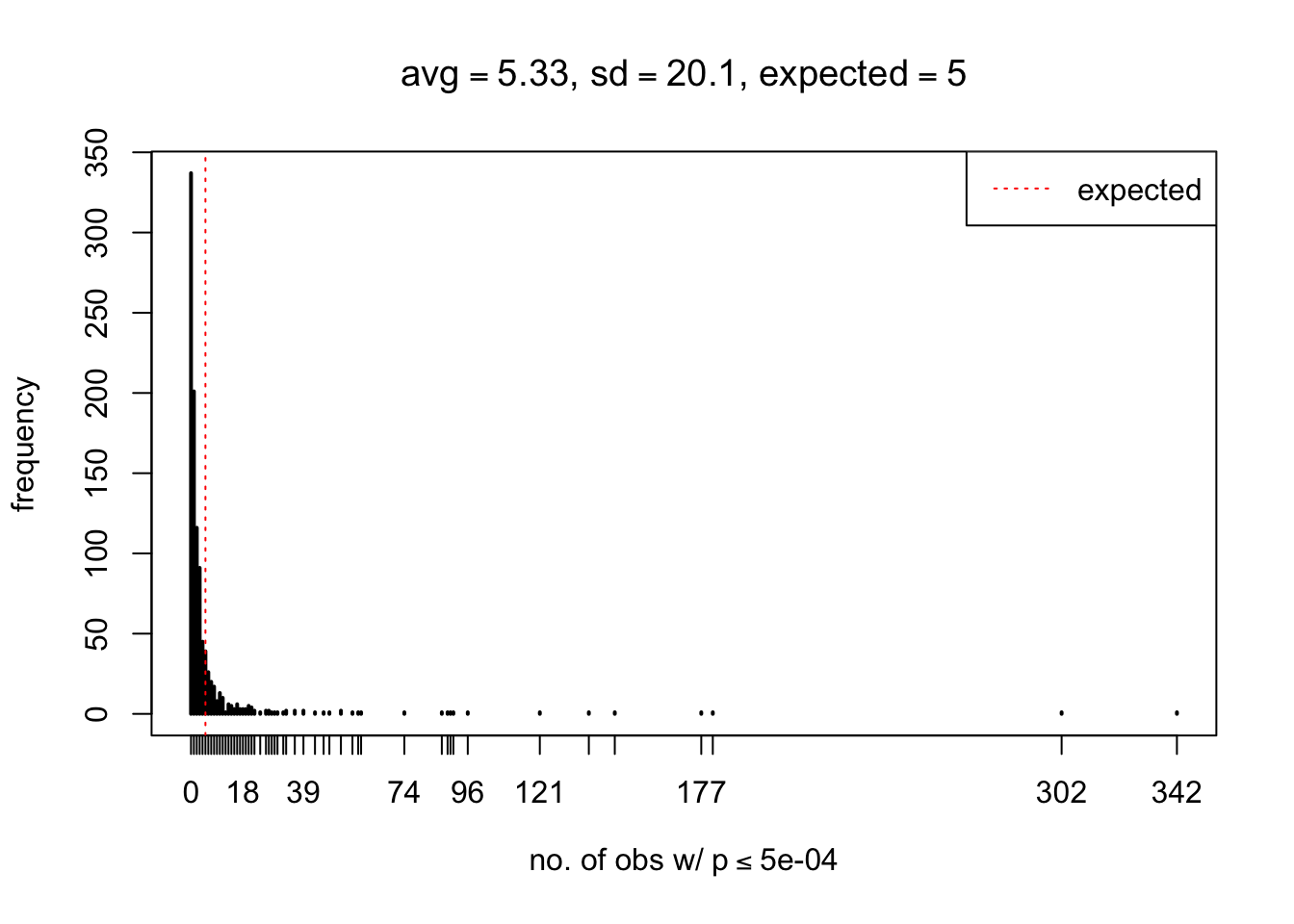
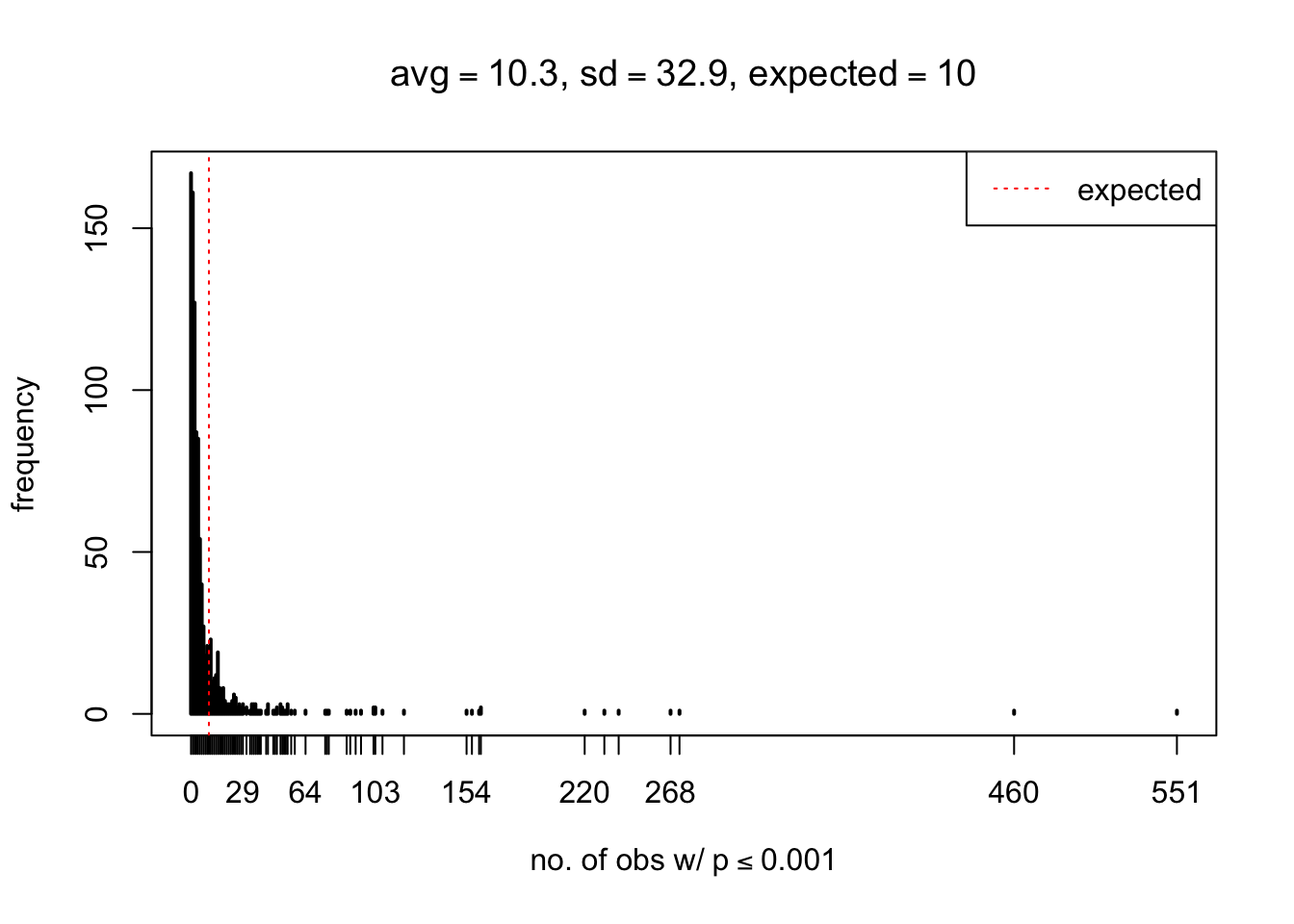
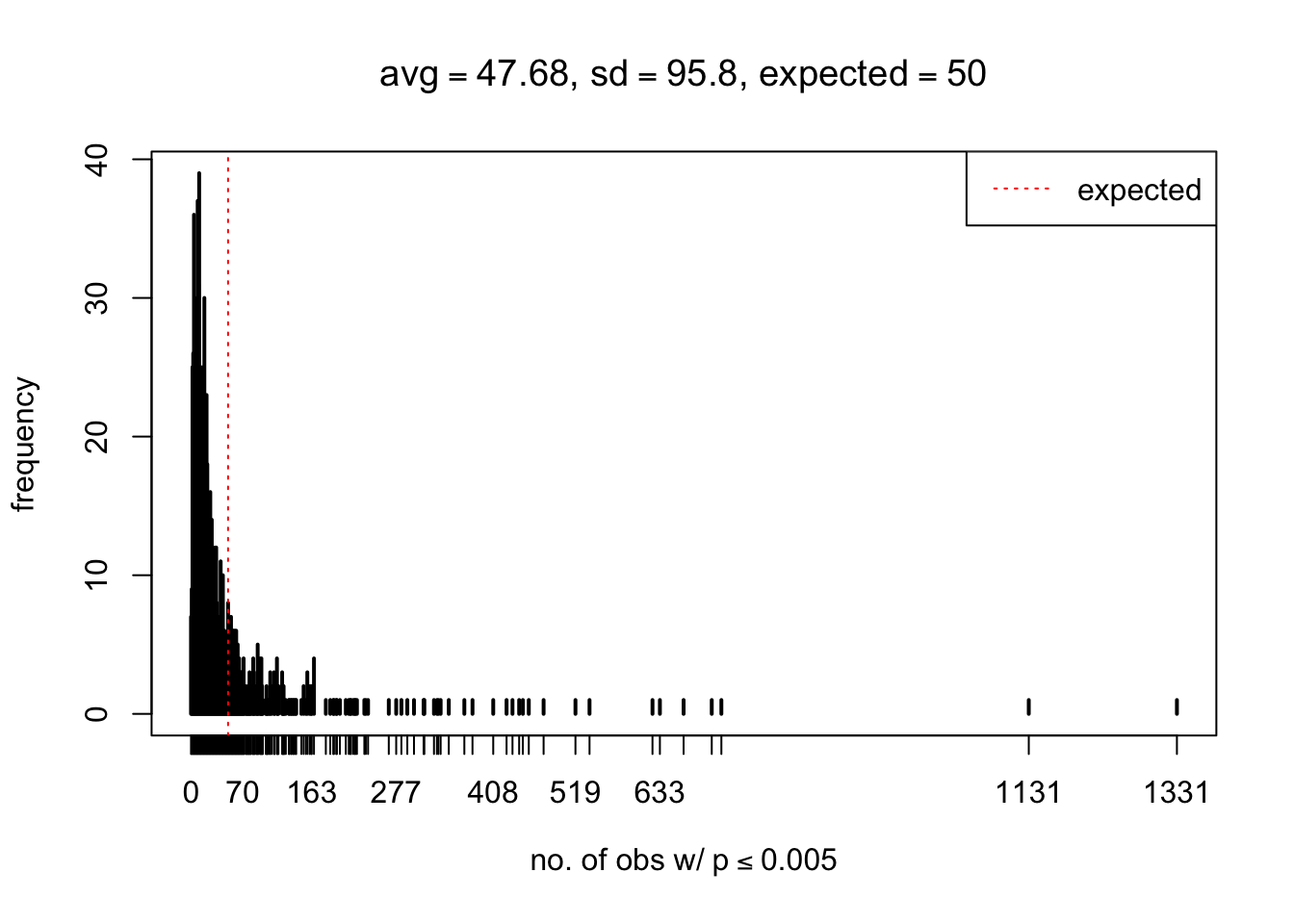
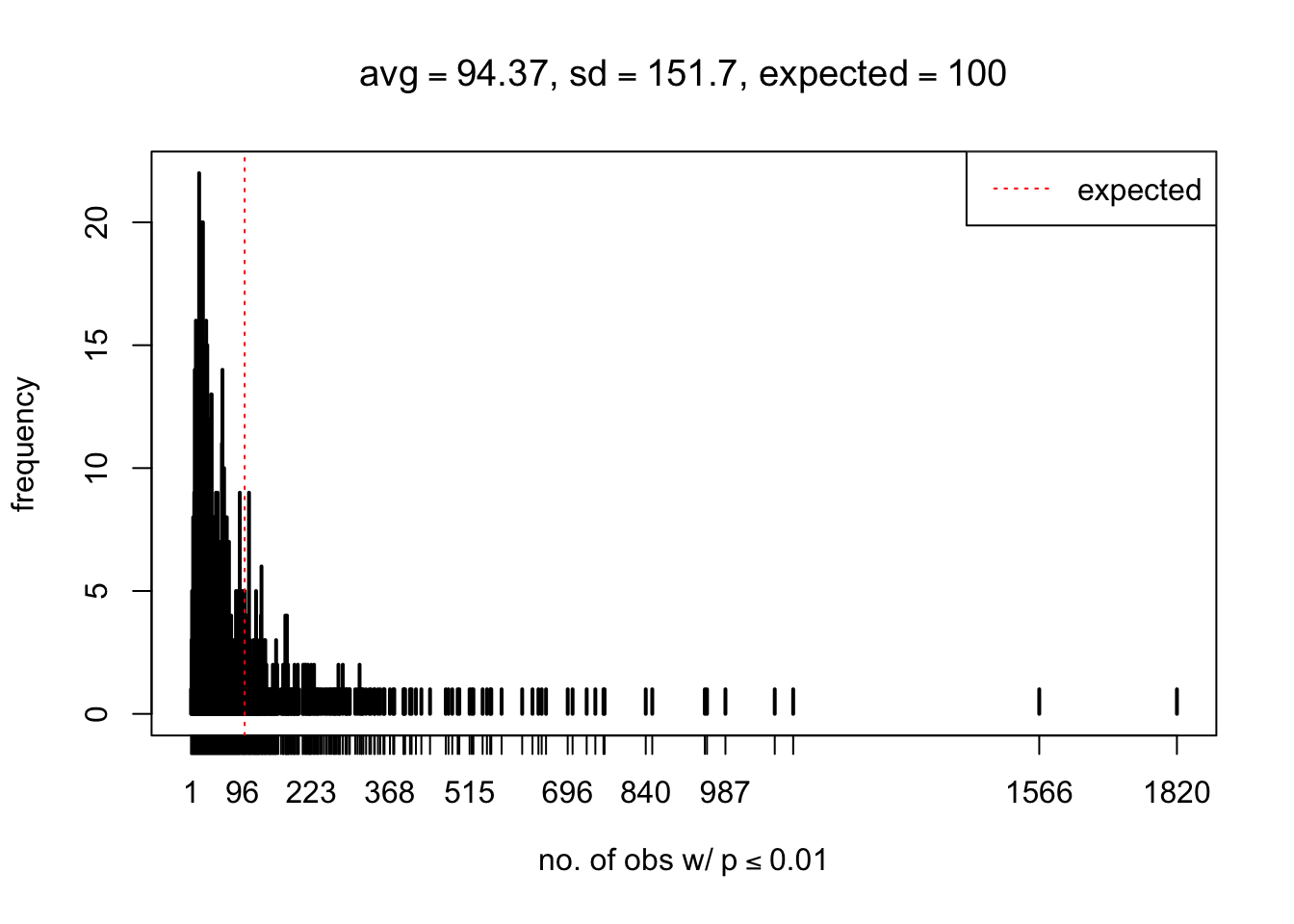
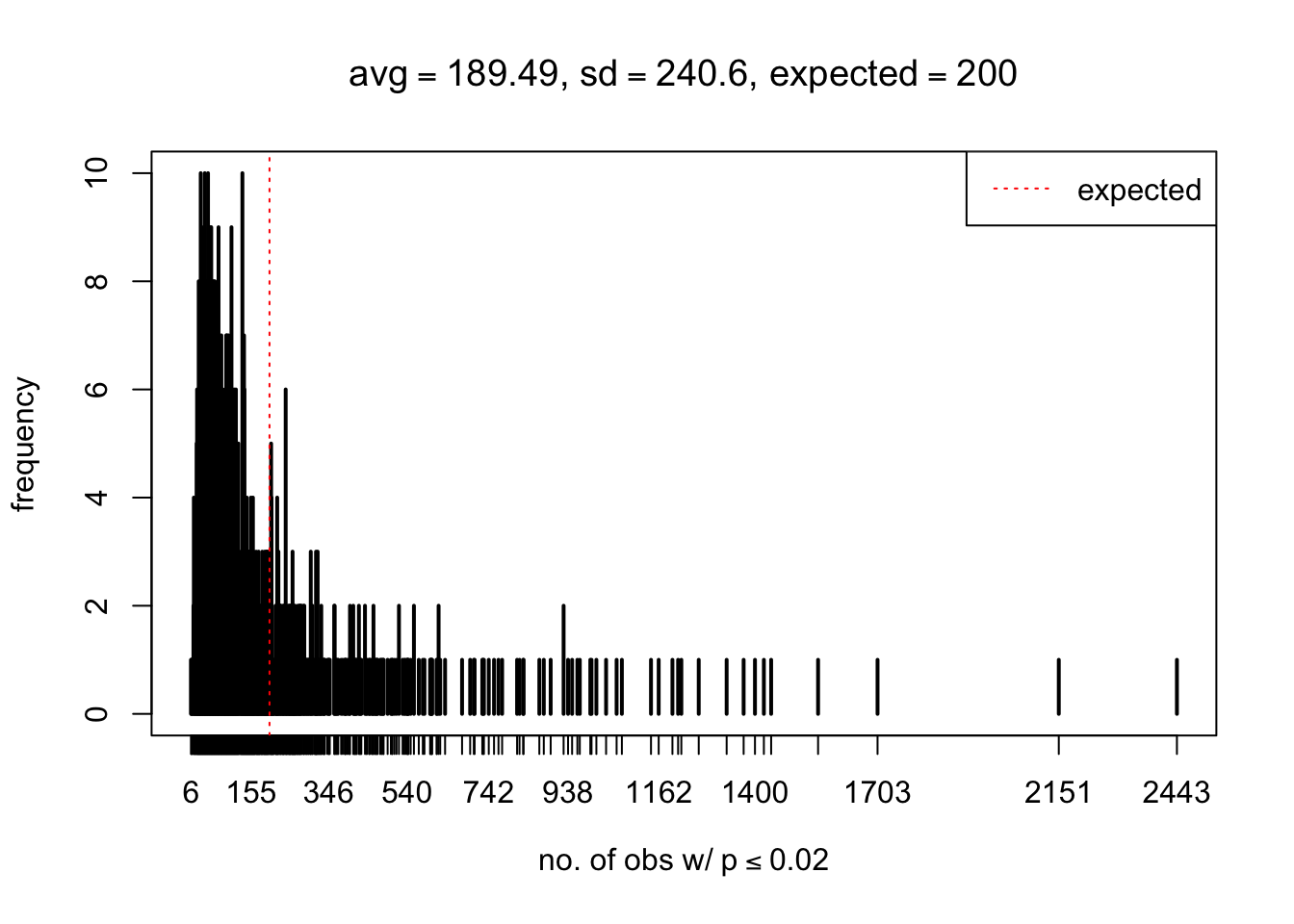
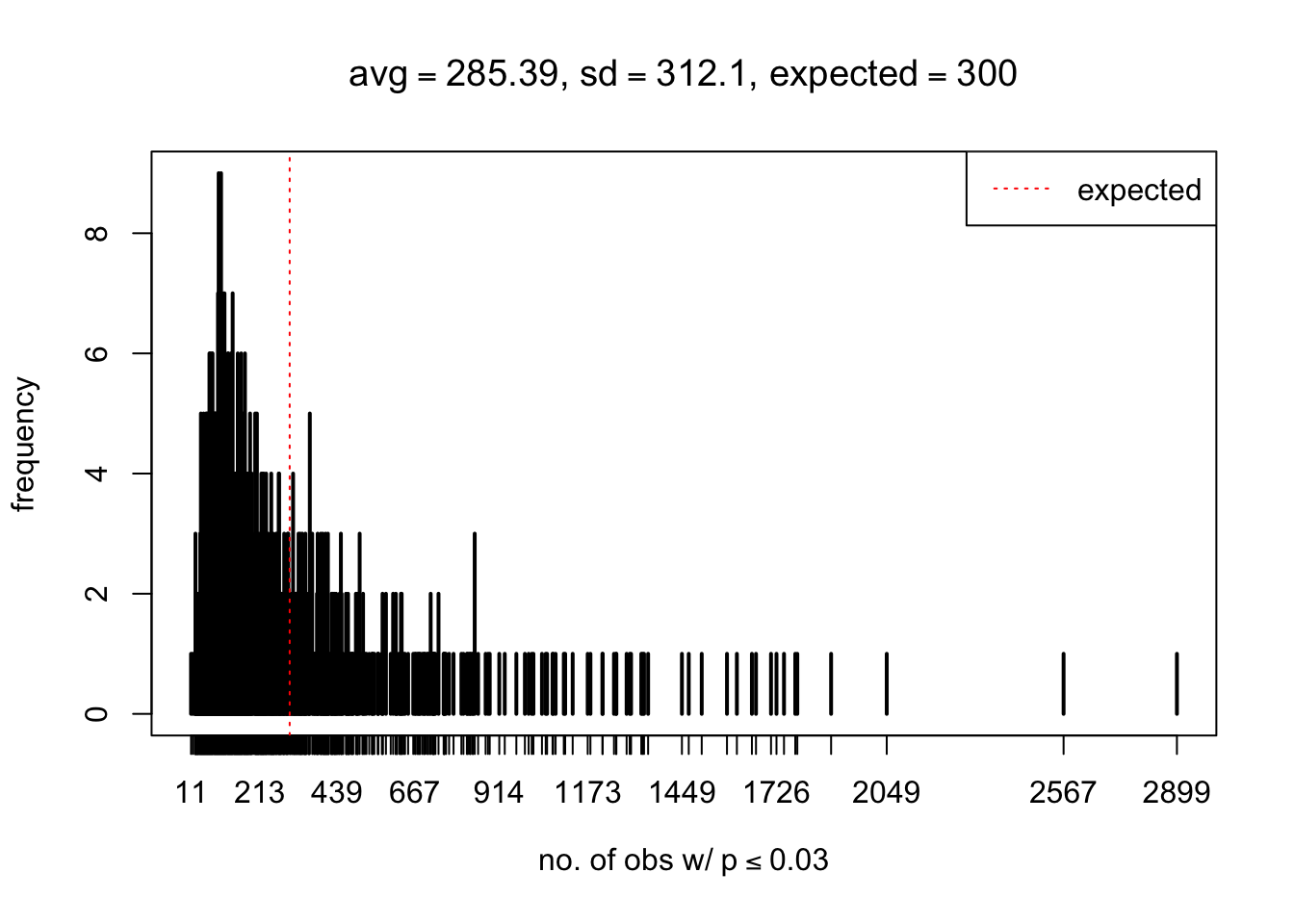
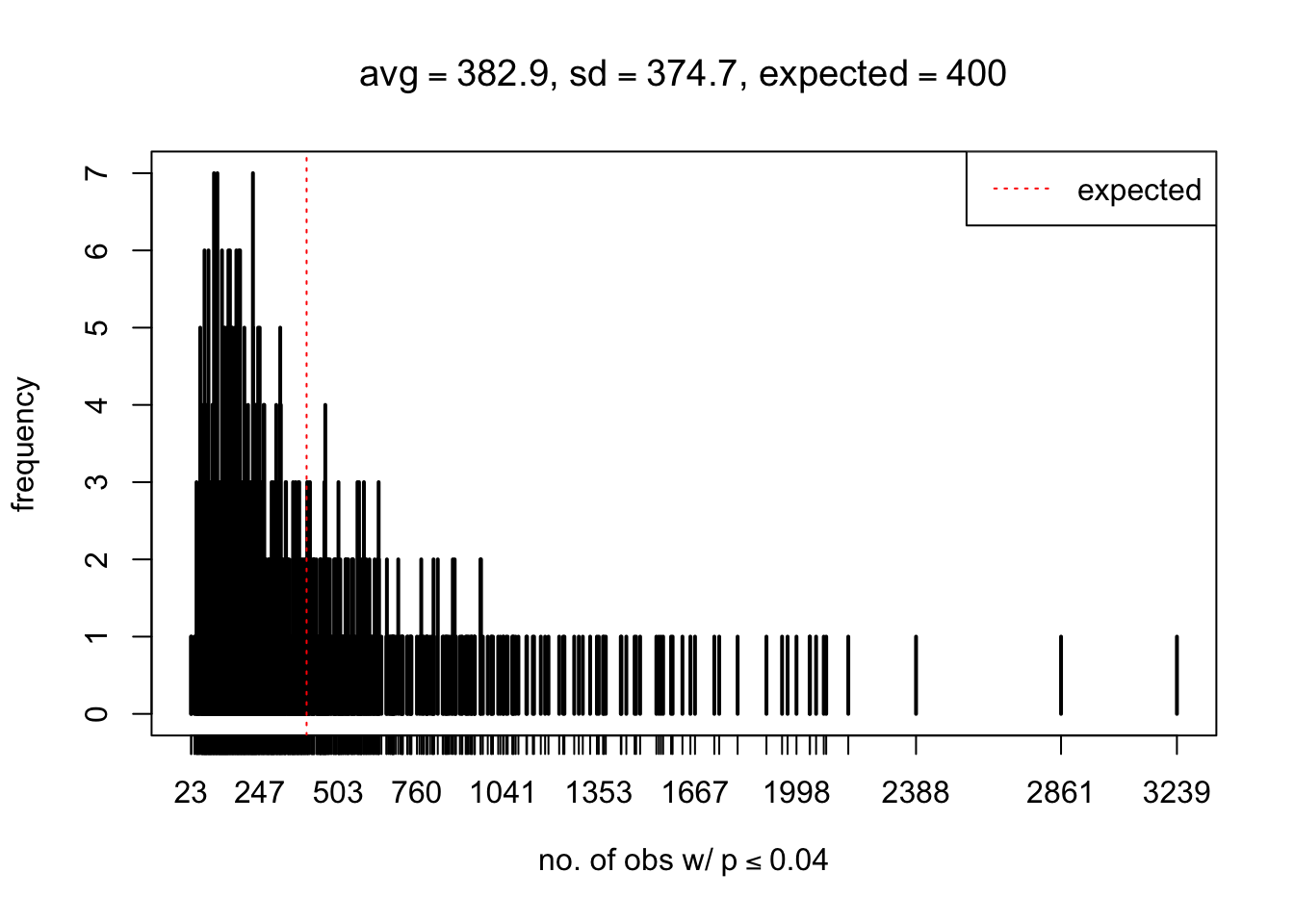
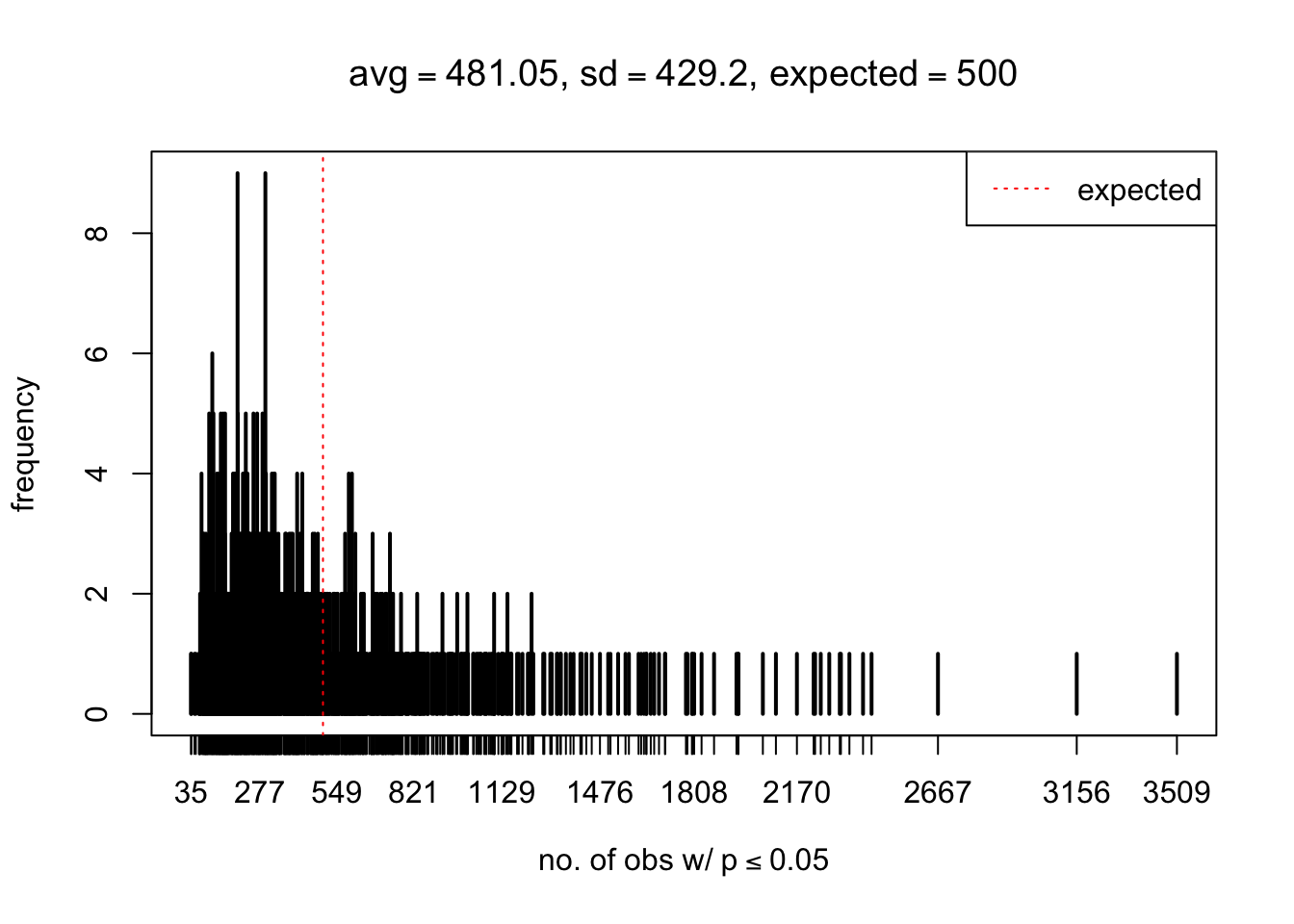
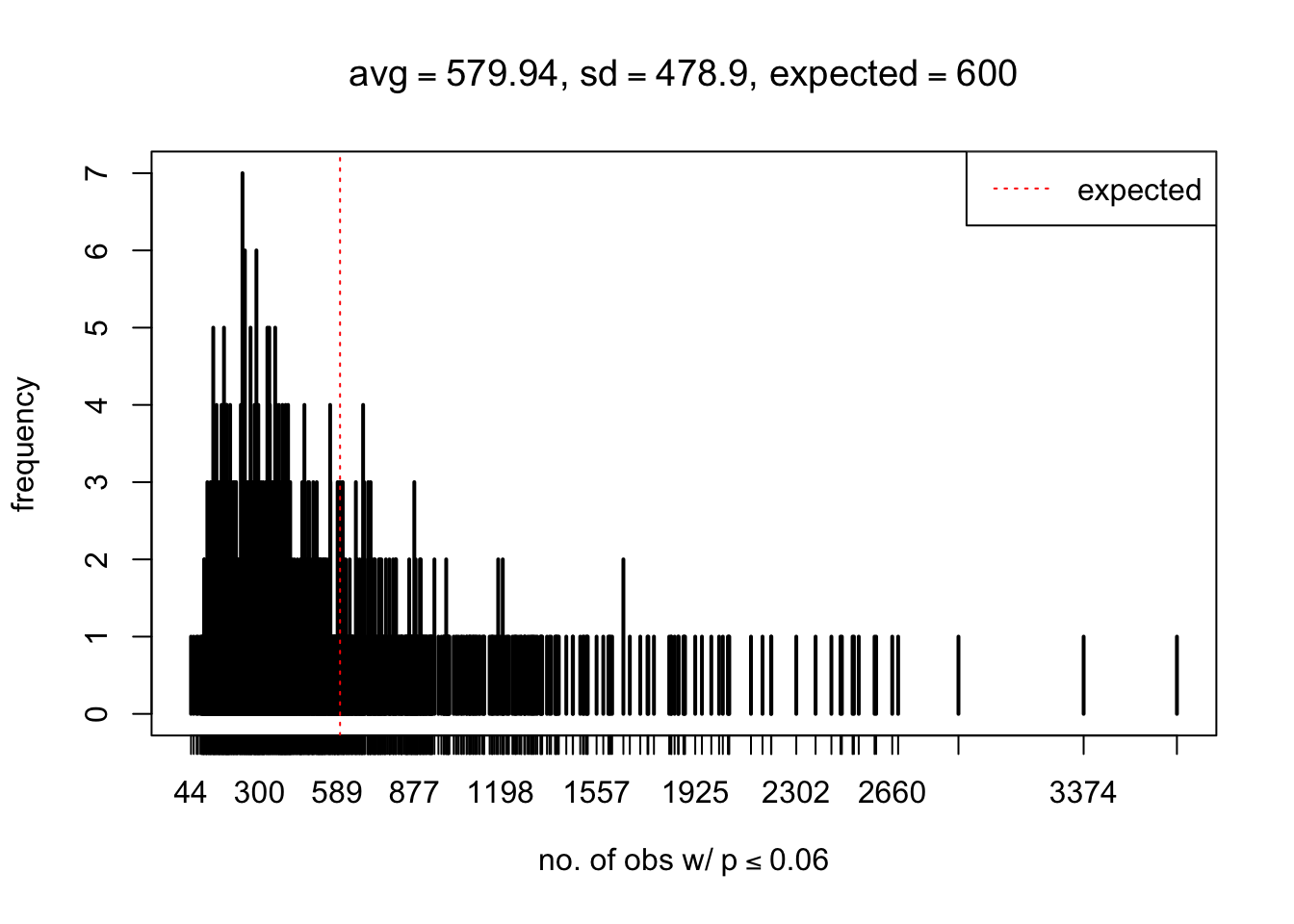
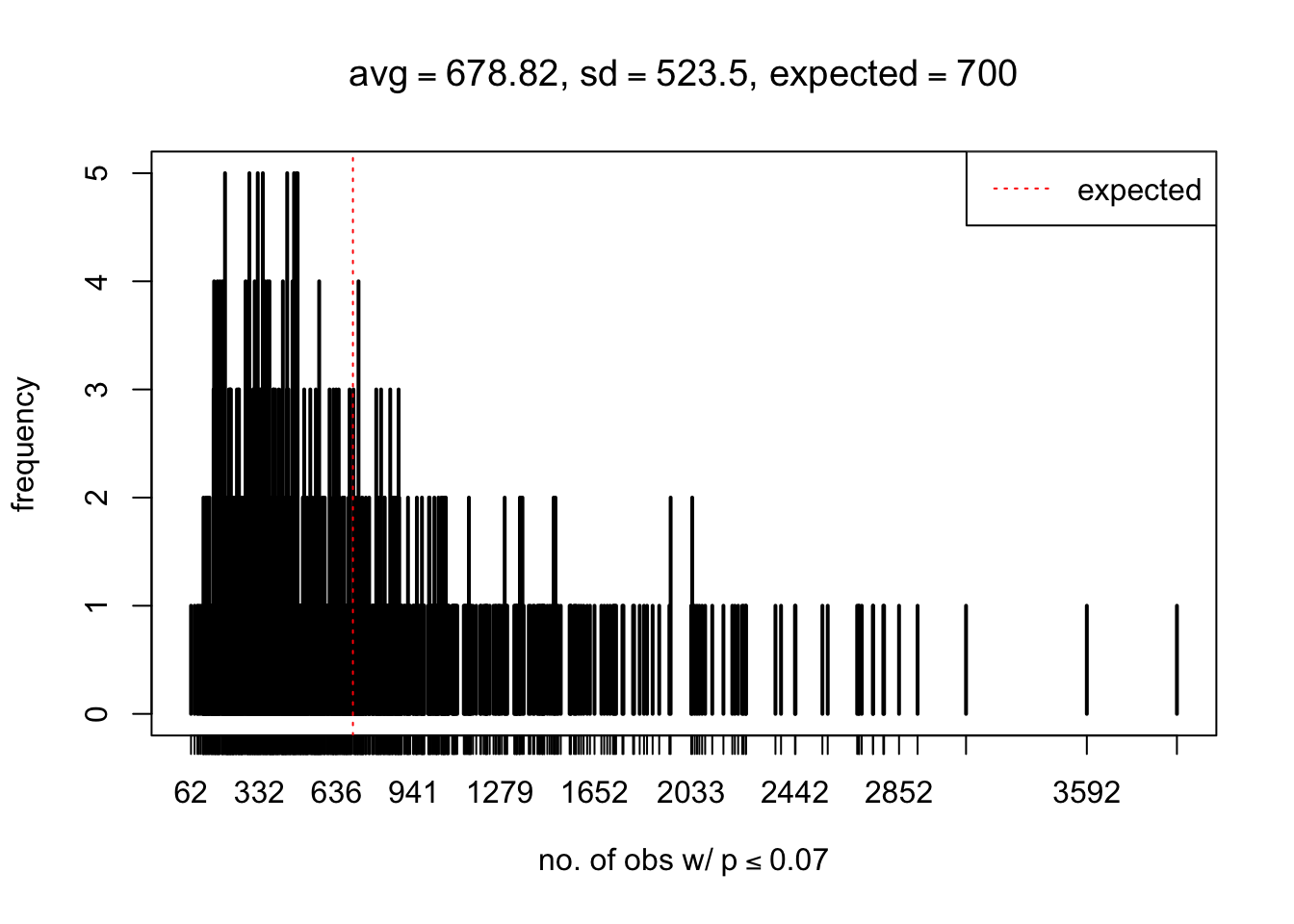
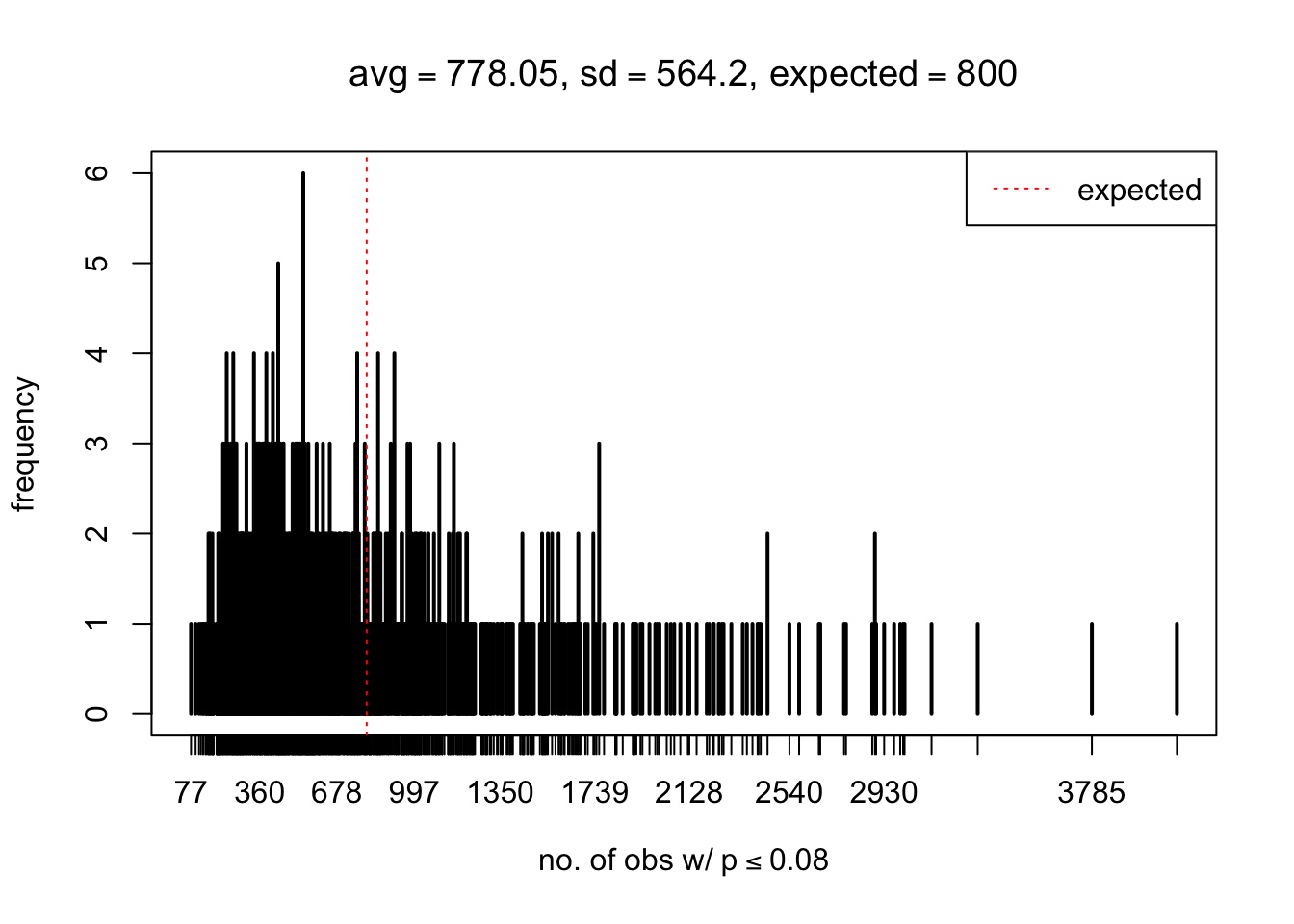
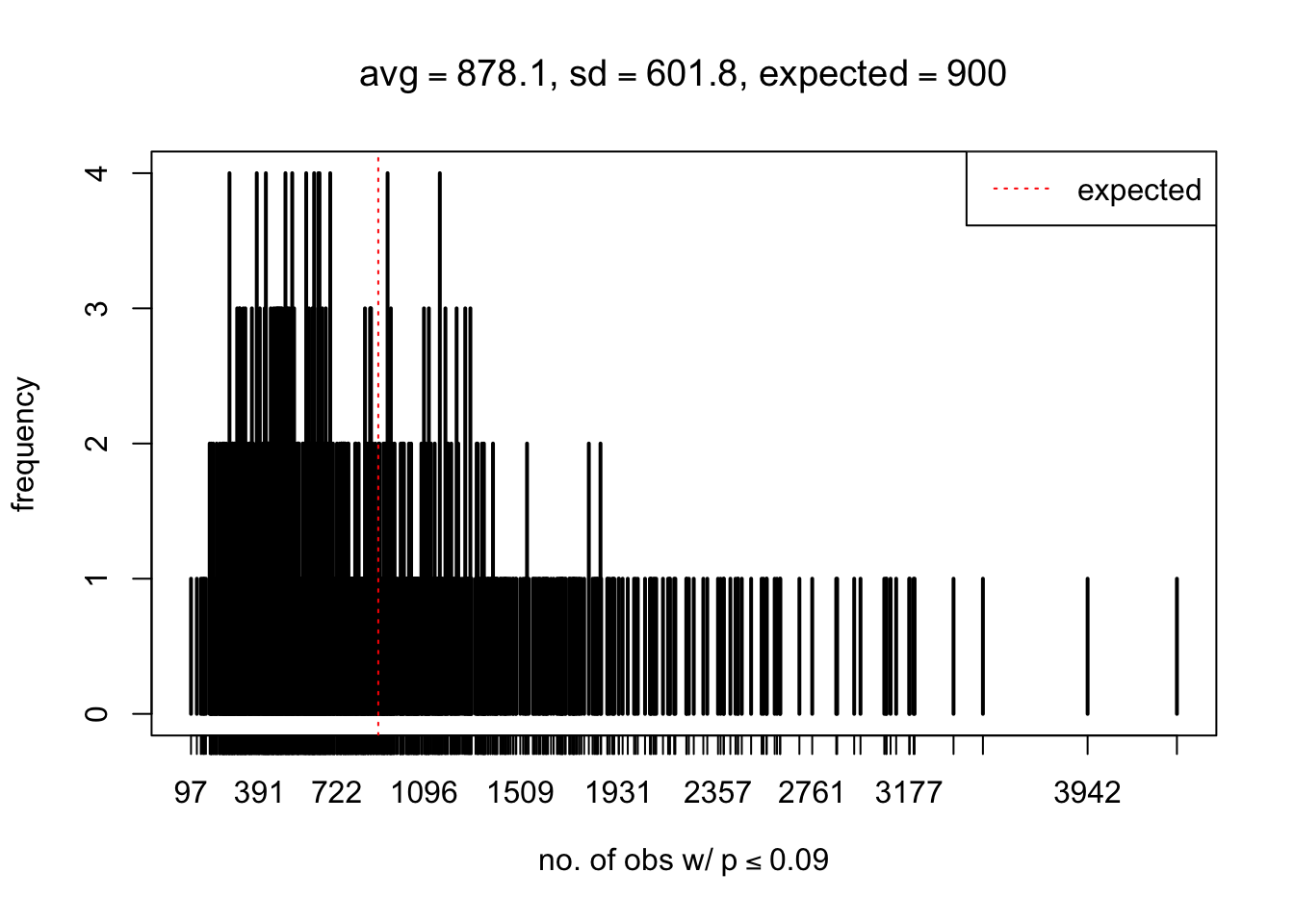
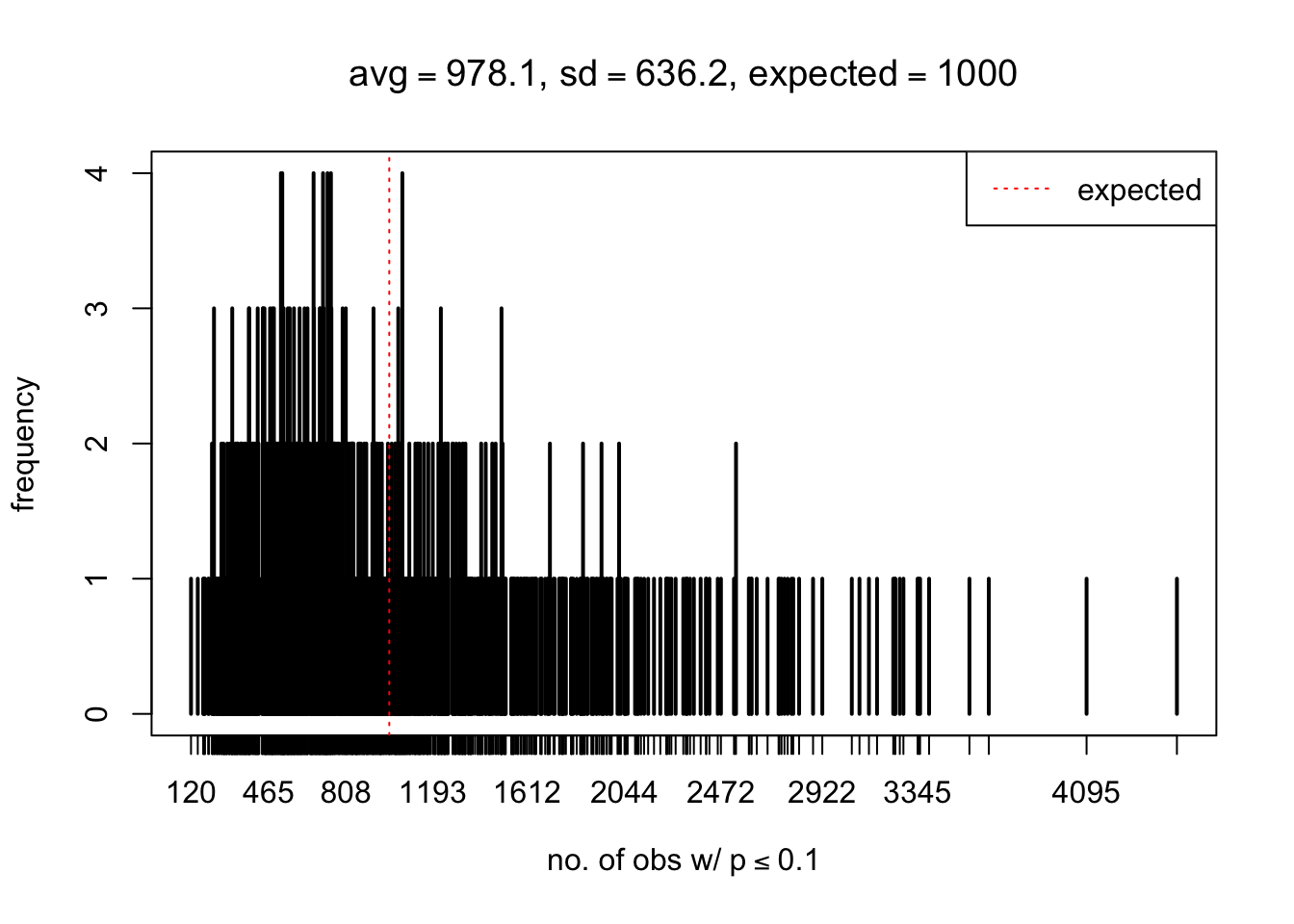
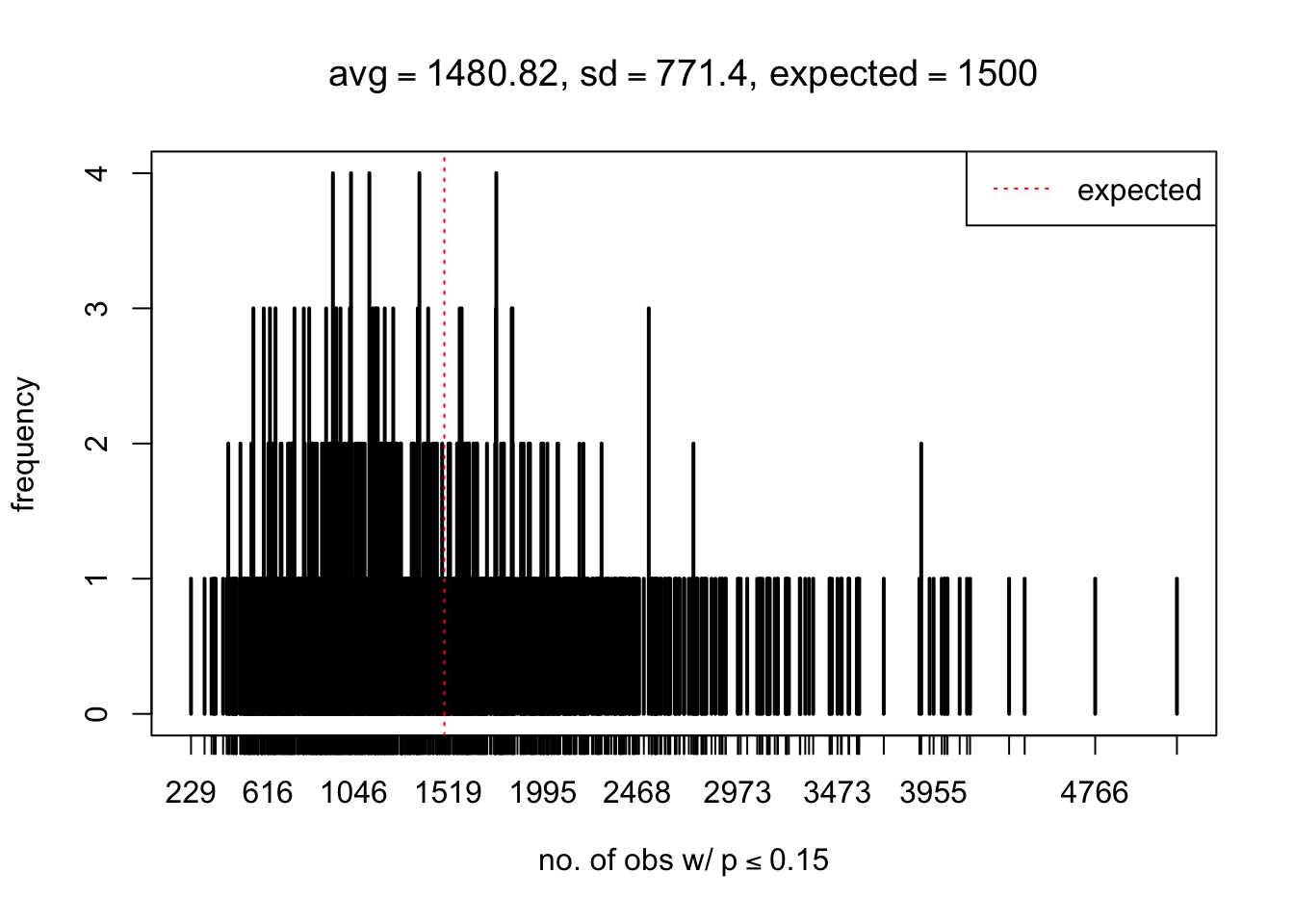
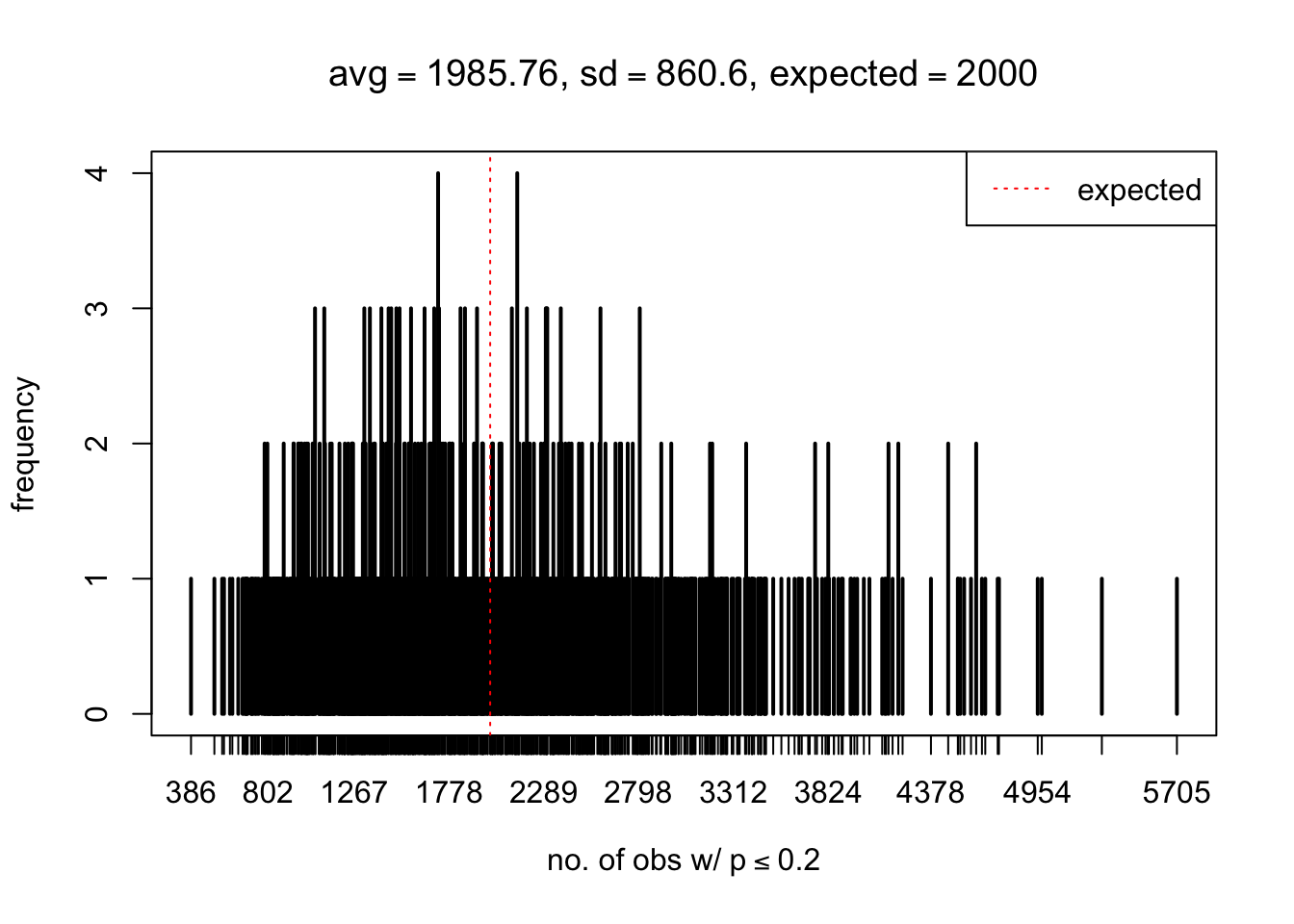
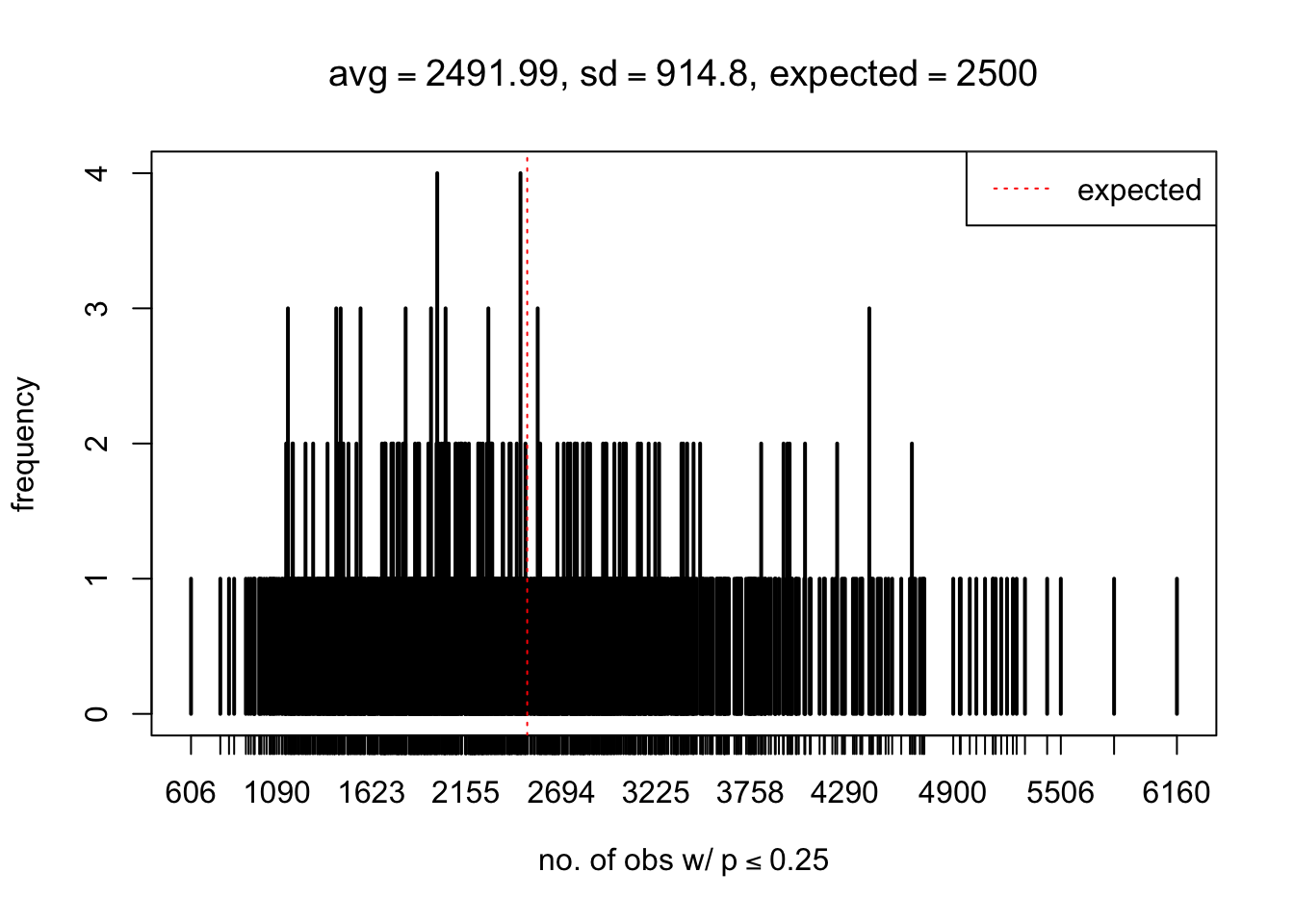
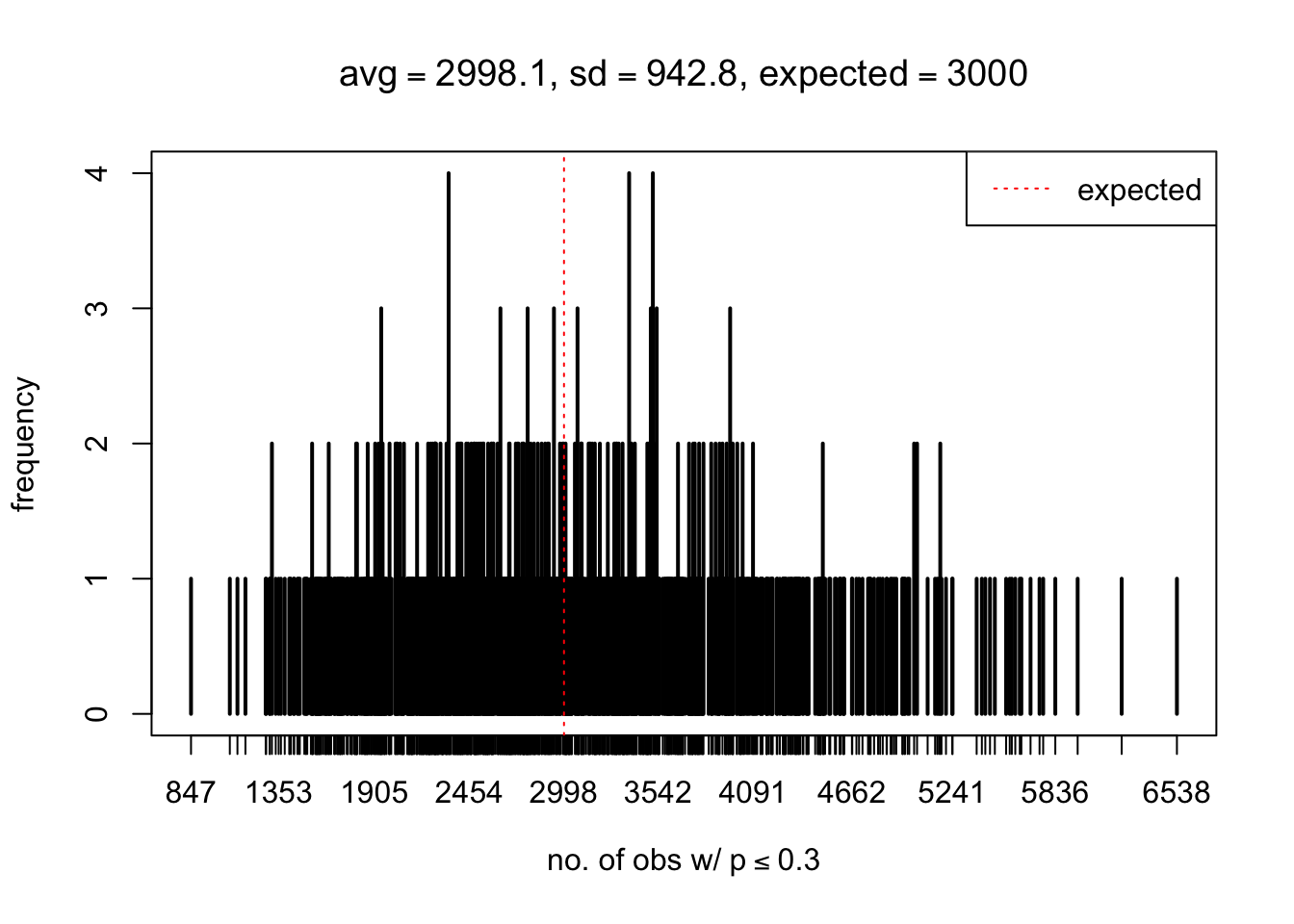
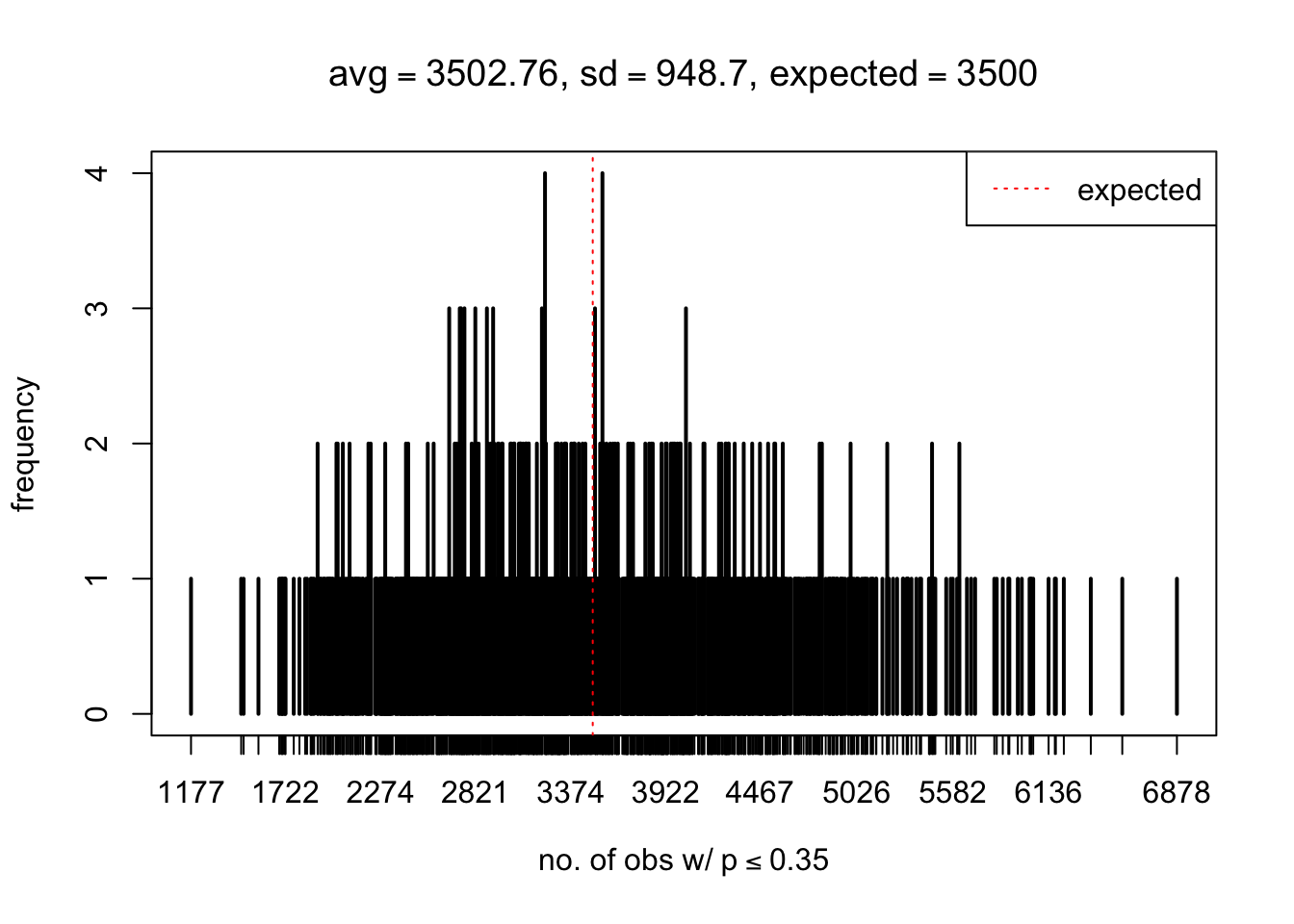
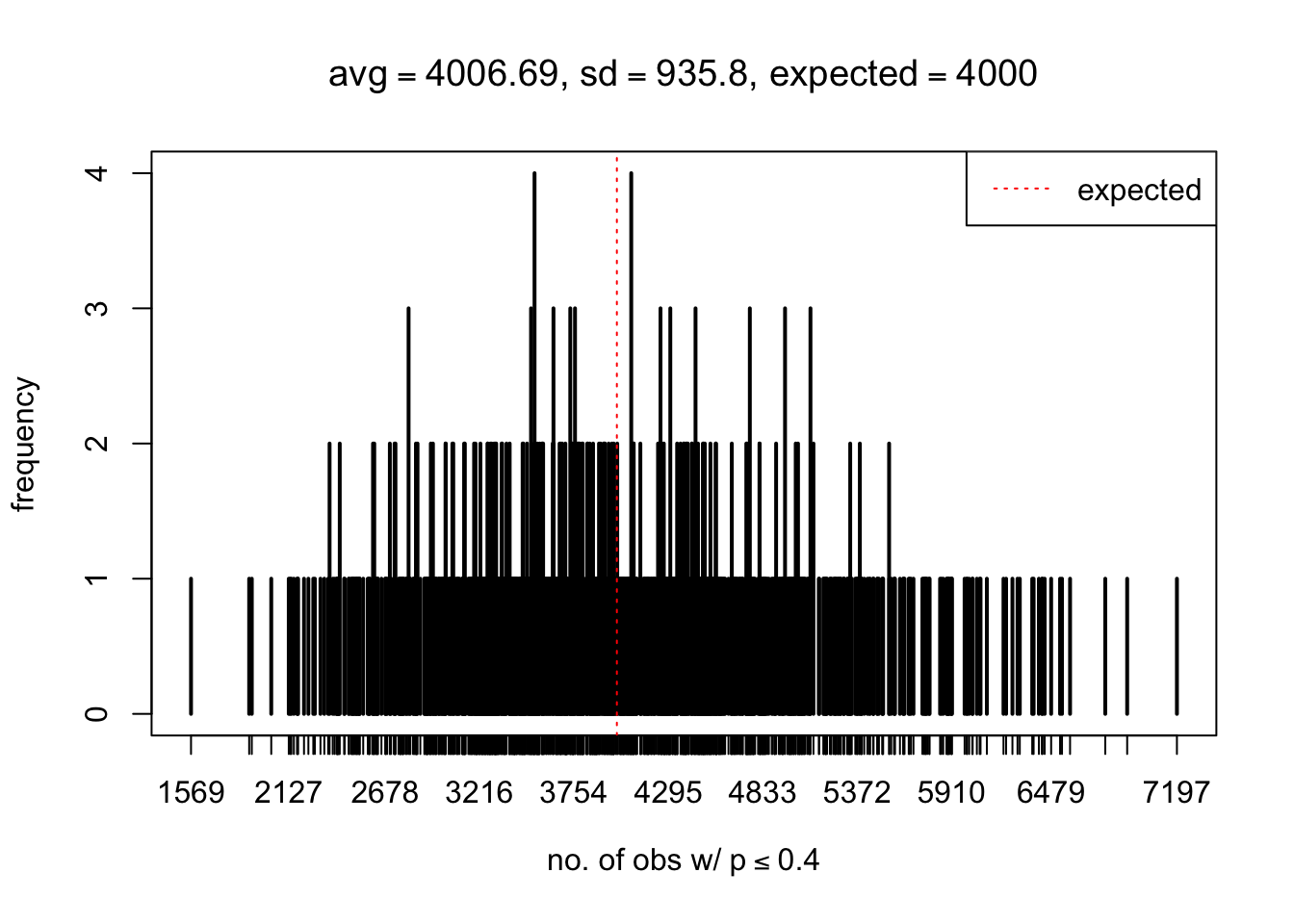
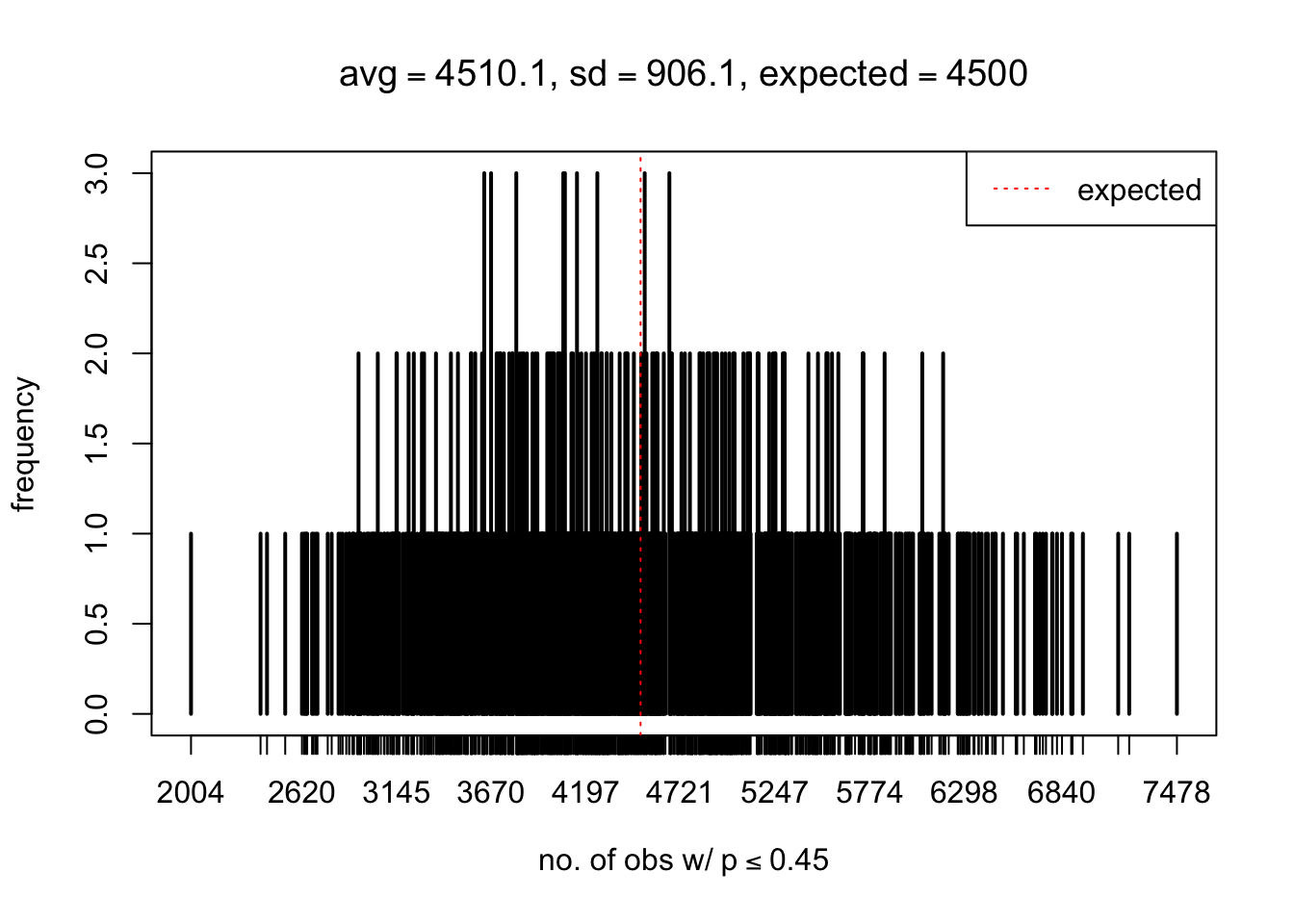
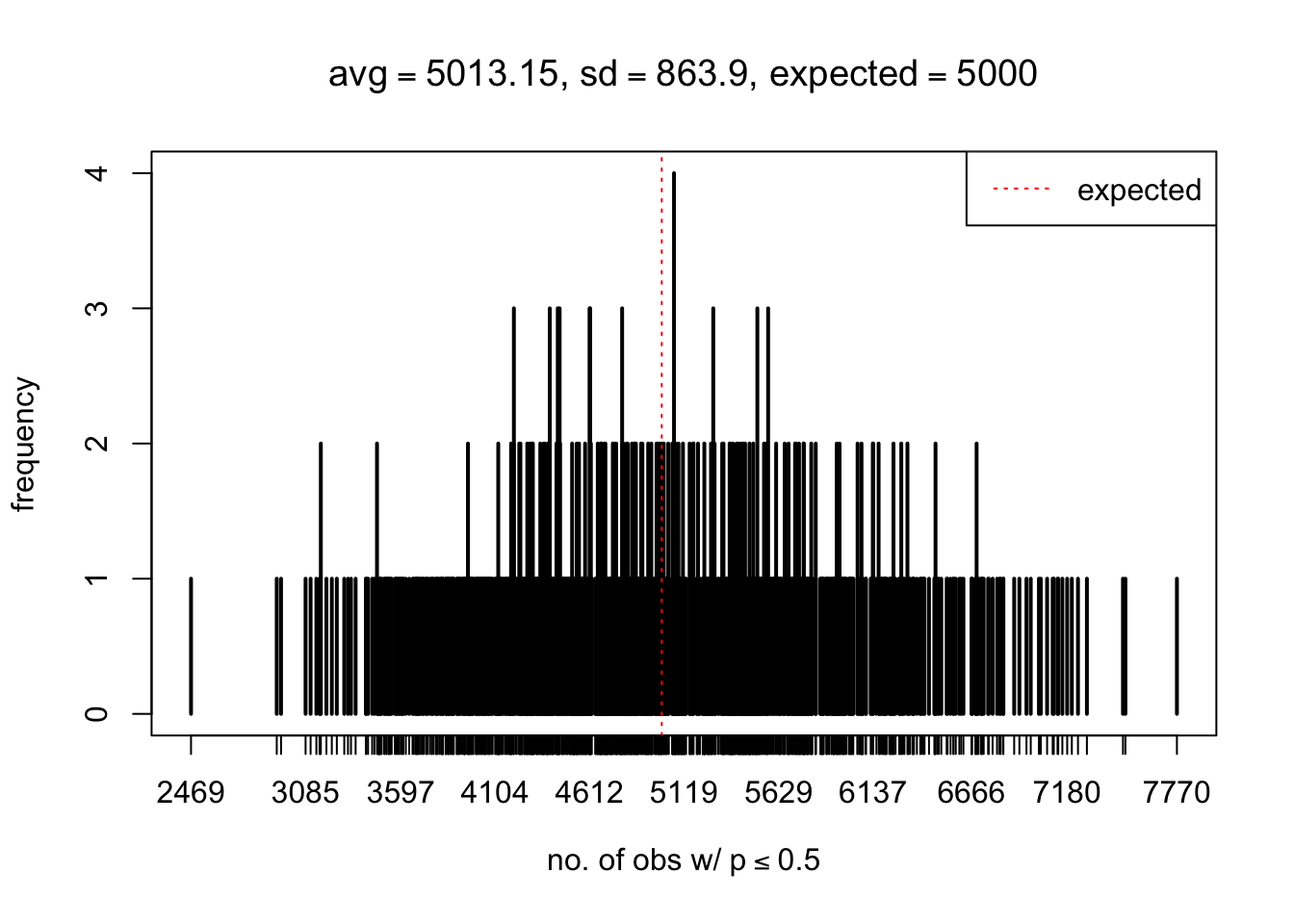
As Prof. Stein pointed, if the marginal distribution is correct then the expected number exceeding any threshold should be correct. So if the tail is “usually”" deflated, it should be that with some small probability there are many large \(z\)-scores (even in the tail). Therefore, if “on average” we have the right number of large \(z\)-scores/small \(p\)-values, and “usually” we have too few, then “rarely” we should have too many.
For the first plot, for example, each simulation run we have \(10\)K \(p\)-values from \(10\)K genes simulated under the global null by sampling 5 livers vs 5 livers. We are using threshold \(= 5e-4\). The \(p\)-values, as shown by the previous simulations, should be generally inflated, but the extreme p-values should be deflated more often than inflated. Therefore, under the global null, on average, we should observe \(5e-4 \times 10K = 5\) extreme p-values under the threshold, yet most of the time we should observe less than this average, and only occasionally we should observe far more than this average. This is exactly what we have seen from 1000 simulation runs. The red dotted line is 5, the expected number. Out of 1000 runs, most of them generated less than 5 extreme p-values, yet occasionally we have far more than 5 extreme p-values, some of which could be as many as 300. On average we have 5.33 extreme p-values, which is close to the expected 5. Other plots are similar.
The R code to generate both \(p\)-value tables is in p_null_liver.R
Session Information
sessionInfo()R version 3.4.3 (2017-11-30)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS High Sierra 10.13.2
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.4/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.4/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] compiler_3.4.3 backports_1.1.2 magrittr_1.5 rprojroot_1.3-1
[5] tools_3.4.3 htmltools_0.3.6 yaml_2.1.16 Rcpp_0.12.14
[9] stringi_1.1.6 rmarkdown_1.8 knitr_1.17 git2r_0.20.0
[13] stringr_1.2.0 digest_0.6.13 workflowr_0.8.0 evaluate_0.10.1This R Markdown site was created with workflowr