Diagnostic Plot for Uniform Distribution
Lei Sun
2017-05-02
Last updated: 2017-12-21
Code version: 6e42447
Introduction
Suppose we have \(n\) iid samples presumably from \(\text{Uniform}\left[0, 1\right]\). Our goal is to make a diagnostic plot to check if they are truly coming from \(\text{Uniform}\left[0, 1\right]\).
Plotting positions
The basic tool is the Q-Q plot. Basically, we are ploting the sample quantiles against their theoretical quantiles, also called “plotting positions.” But it turns out it’s more complicated than what it appears, because it’s not clear what are the best “theoretical quantiles” or plotting positions. For example, \(\left\{1/n, 2/n, \ldots, n/n\right\}\) appears an obvious option, but if the distribution is normal, the quantile of \(n/n = 1\) is \(\infty\). Even if the distribution is compactly supported, like \(\text{Uniform}\left[0, 1\right]\), the quantile of \(1\) is \(1\), yet the largest sample will always be strictly less than \(1\).
This is called the “plotting positions problem.” It has a long history and a rich literature. Harter 1984 and Makkonen 2008 seem to be two good reviews. Popular choices include \(\left\{\frac{k-0.5}{n}\right\}\), \(\left\{\frac{k}{n+1}\right\}\), \(\left\{\frac{k - 0.3}{n+0.4}\right\}\), or in general, \(\left\{\frac{k-\alpha}{n+1-2\alpha}\right\}\), \(\alpha\in\left[0, 1\right]\), which approximates \(F\left(E\left[X_{(k)}\right]\right)\) for certain \(\alpha\), and includes all above as special cases.
For practical purposes, for \(\text{Uniform}\left[0, 1\right]\) distribution, we are using \(\left\{\frac{1}{n+1}, \frac{2}{n+1}, \ldots, \frac{n}{n+1}\right\}\) as plotting positions for diagnosing \(\text{Uniform}\left[0, 1\right]\). Harter 1984 provided some justification for this choice. In short, \(\text{Uniform}\left[0, 1\right]\) is unique in that it has the property
\[ \displaystyle F\left(E\left[X_{(k)}\right]\right) = E\left[F\left(X_{(k)}\right)\right] = \frac{k}{n + 1} \ , \] where \(X_{(k)}\) is the order statistic.
De-trending the \(0\)-\(1\) line
Another problem is also related to Q-Q plots in general, and especially to the problem we have right now. In uniform Q-Q plots, in Matthew’s words, “current plots are dominated by the trend from 0 to 1,” so it’ would be better to “remove that trend to better highlight the deviations from the expectation.”
The order statistics \(X_{(k)}\) for \(\text{Uniform}\left[0, 1\right]\) follows a beta distribution,
\[ X_{(k)} \sim \text{Beta}\left(k, n+1-k\right) \ , \]
which has the mean and variance as
\[ \begin{array}{rcll} E\left[X_{(k)}\right] & = & \displaystyle\frac{k}{n+1} &;\\ Var\left(X_{(k)}\right) &=& \displaystyle\frac{k(n - k + 1)}{\left(n+1\right)^2\left(n + 2\right)} &. \end{array} \]
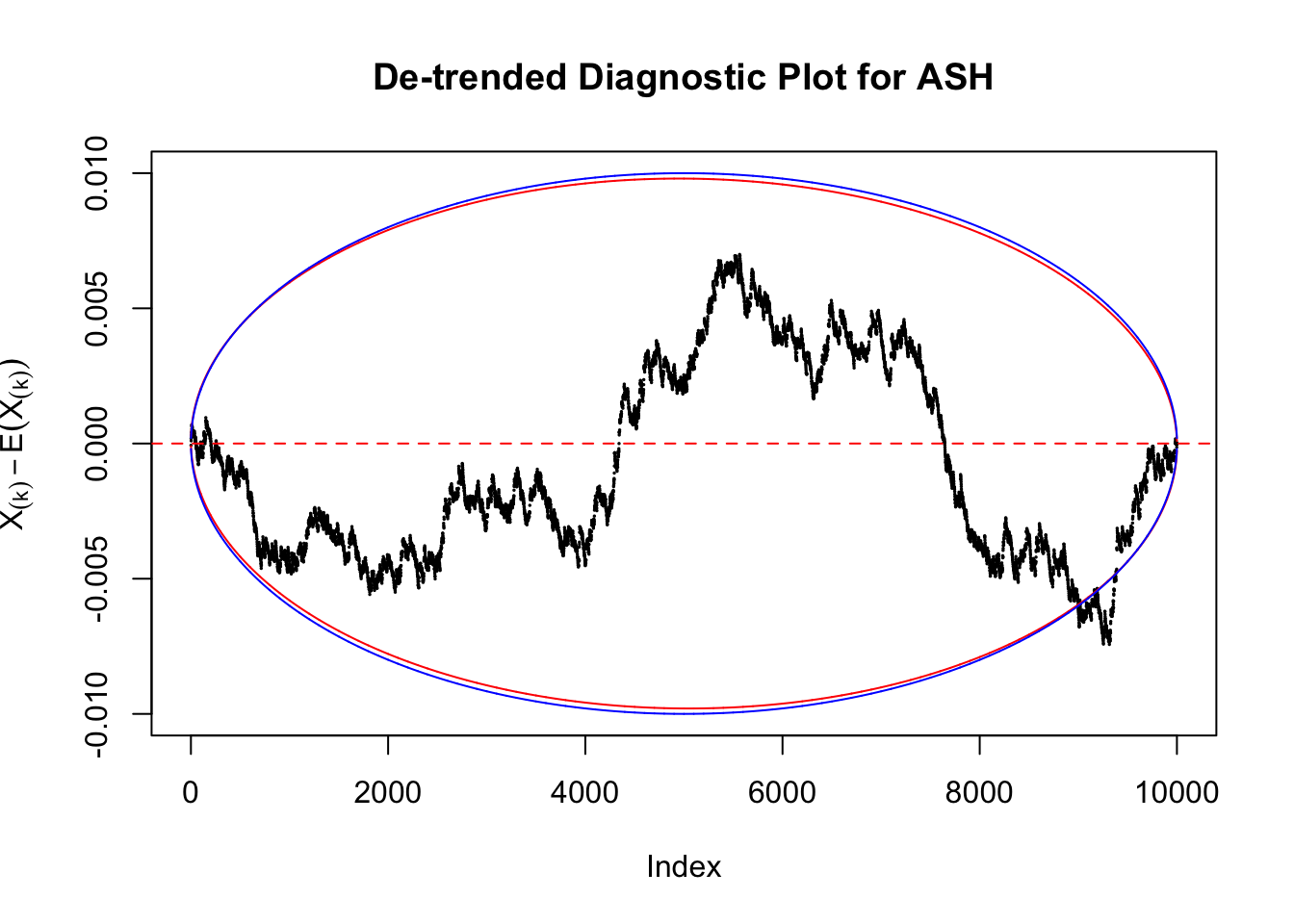
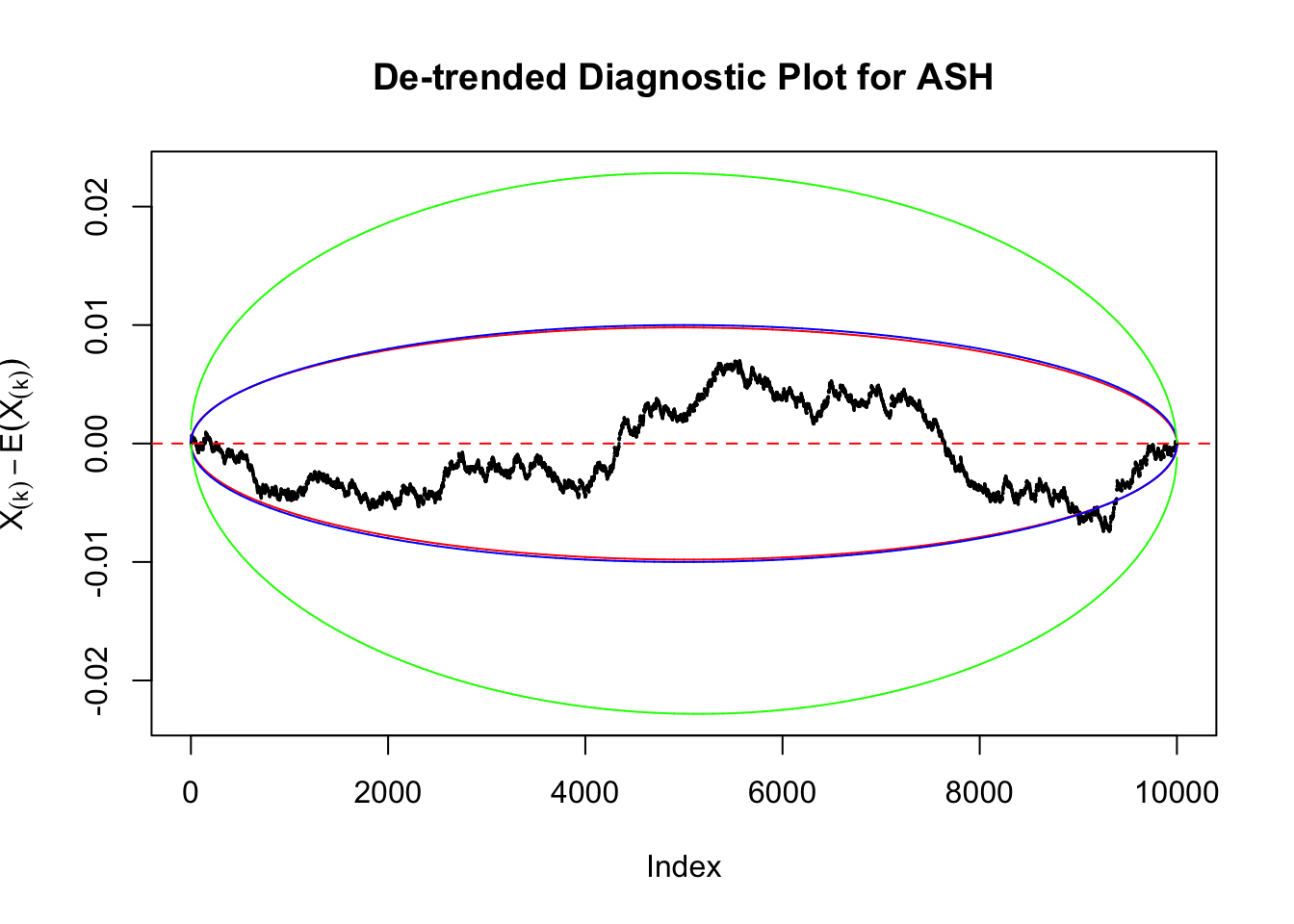
Therefore, we can plot \(X_{(k)} - E\left[X_{(k)}\right]\) along with two error bounds. One choice of the error bounds is to use \(\pm2\sqrt{Var\left(X_{(k)}\right)}\) (in blue); another is to use the \(\alpha / 2\) and \(1-\alpha/2\) quantiles of \(\text{Beta}\left(k, n+1-k\right)\) (in red). Points outside the error bounds thus indicate deviation from the uniform distribution. This plot can be called the de-trended plot.
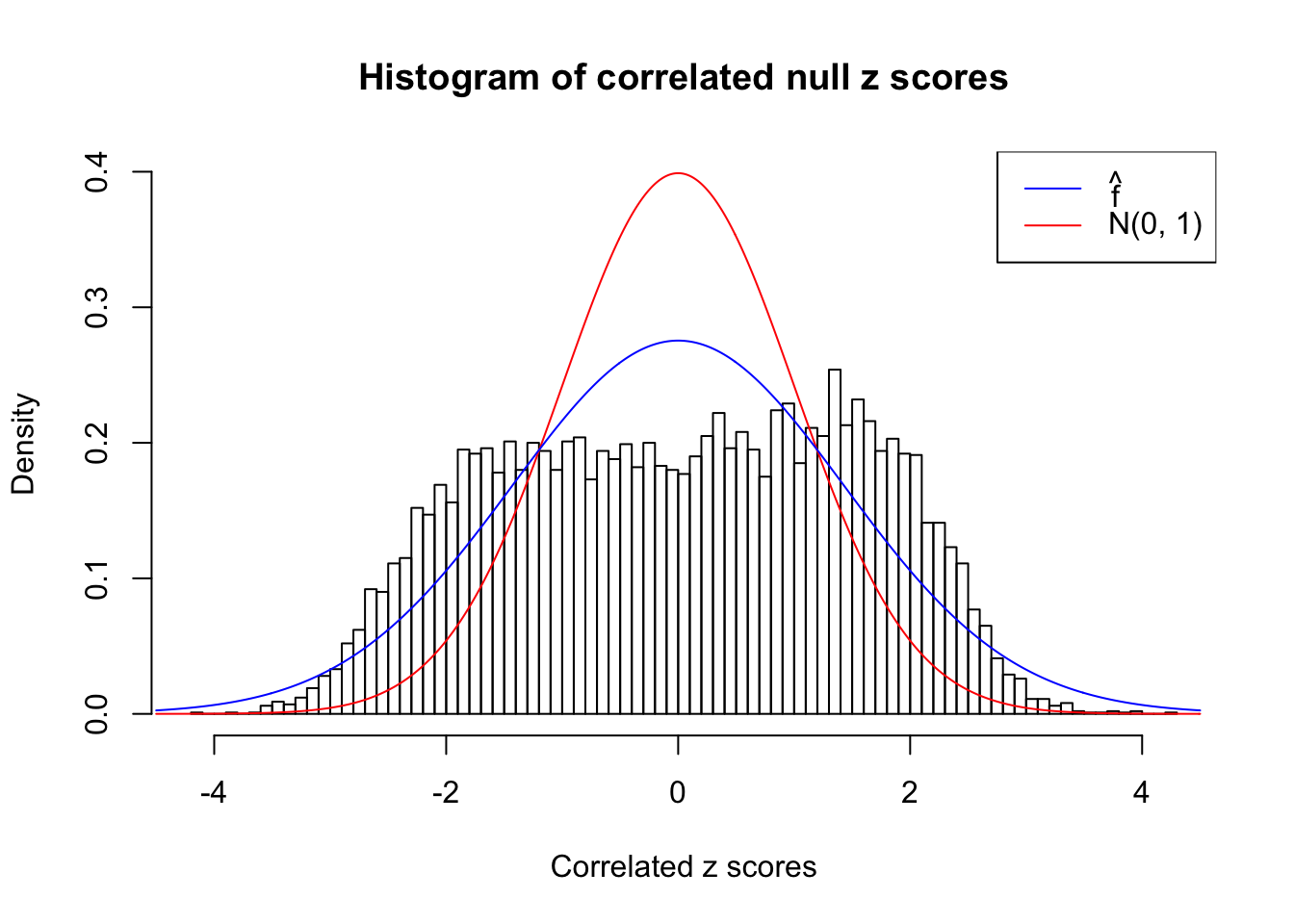
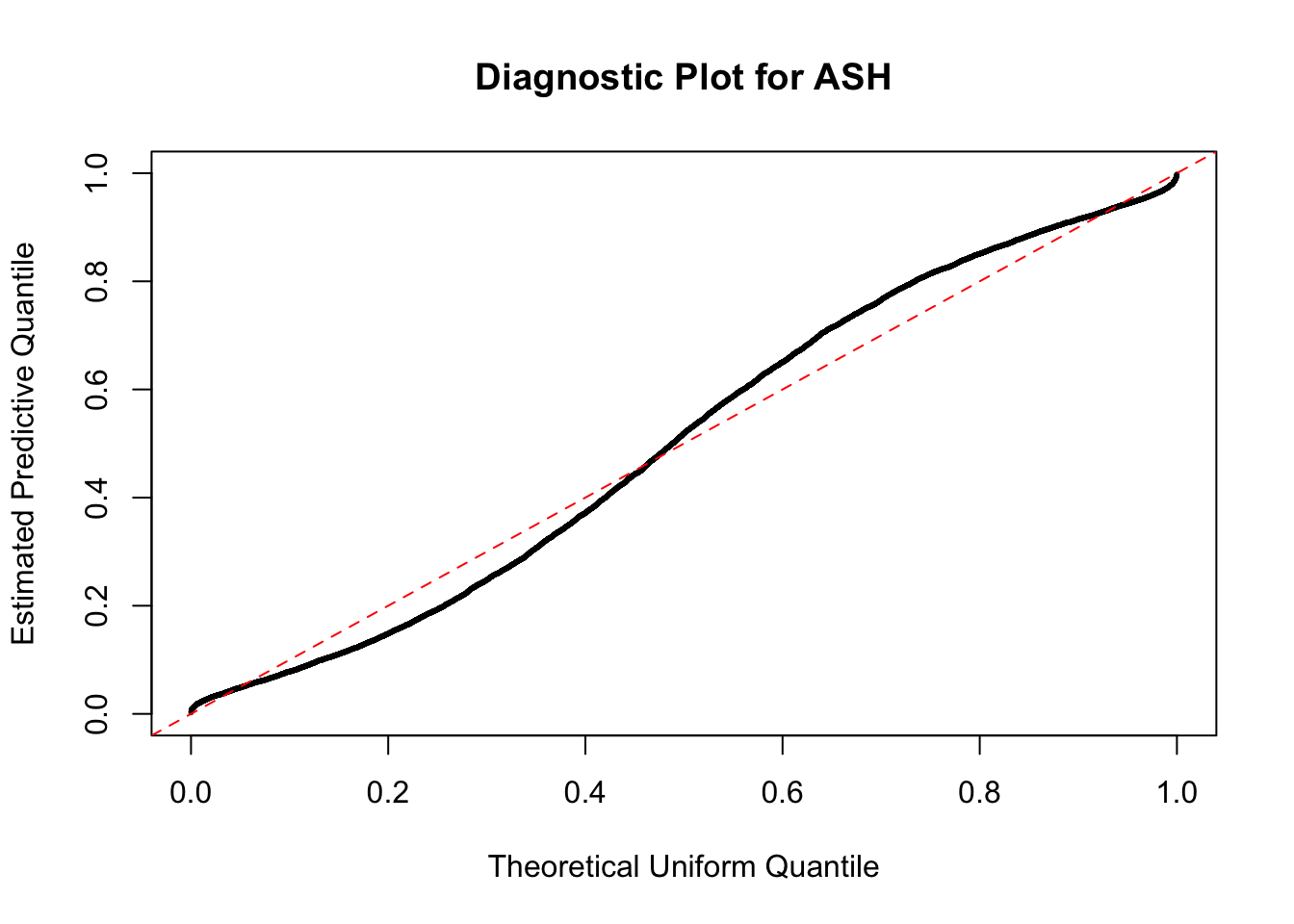
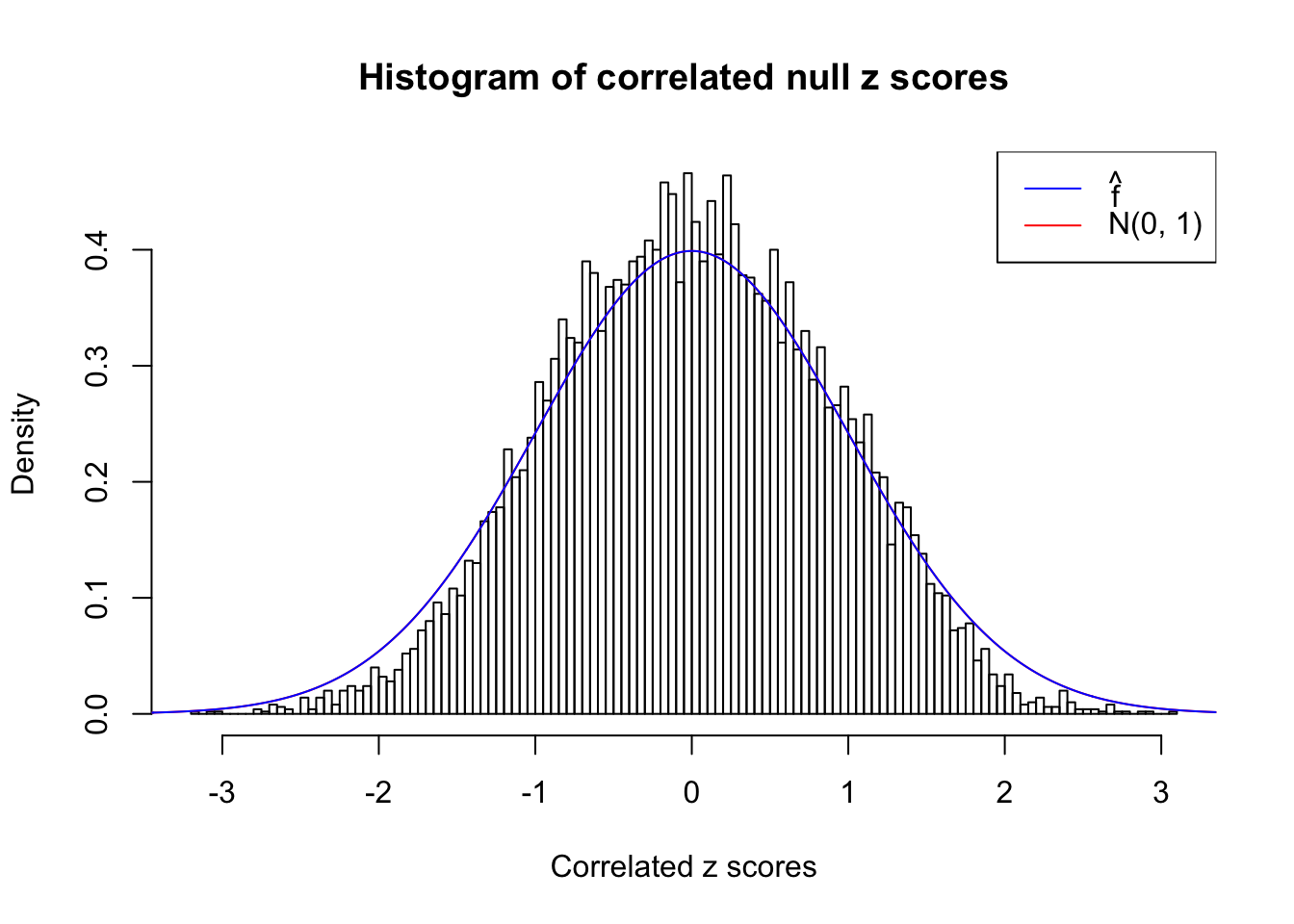
As an example, here is a data set of \(10K\) null \(z\) scores distorted by correlation. We apply ASH to this data set. Since the empirical distribution of these \(z\) scores are highly non-normal due to correlation, presumably ASH with normal prior components and normal likelihood wouldn’t fit this data set well.
z = read.table("../output/z_null_liver_777.txt")z.33 = as.numeric(z[33, ])library(ashr)
fit = ash.workhorse(z.33, 1, method = "fdr", mixcompdist = "normal")
cdfhat = plot_diagnostic(fit, plot.it = FALSE)The histogram of the data set is plotted as follows, as compared with the density of \(N(0, 1)\). In this case since \(\hat s\equiv 1\), all \(\hat z_j\) share the same estimated predictive density, defined as
\[ \hat f = \hat g * N(0, \hat s_j^2 \equiv 1) \ . \]
\(\hat f(x)\) at a given set of \(x\) positions can be evaluated using the following R code.
fhat = function(ash.fit, x, sebetahat = 1) {
data = ashr::set_data(x, sebetahat, ash.fit$data$lik, ash.fit$data$alpha)
return(ashr:::dens_conv.default(ash.fit$fitted_g, data))
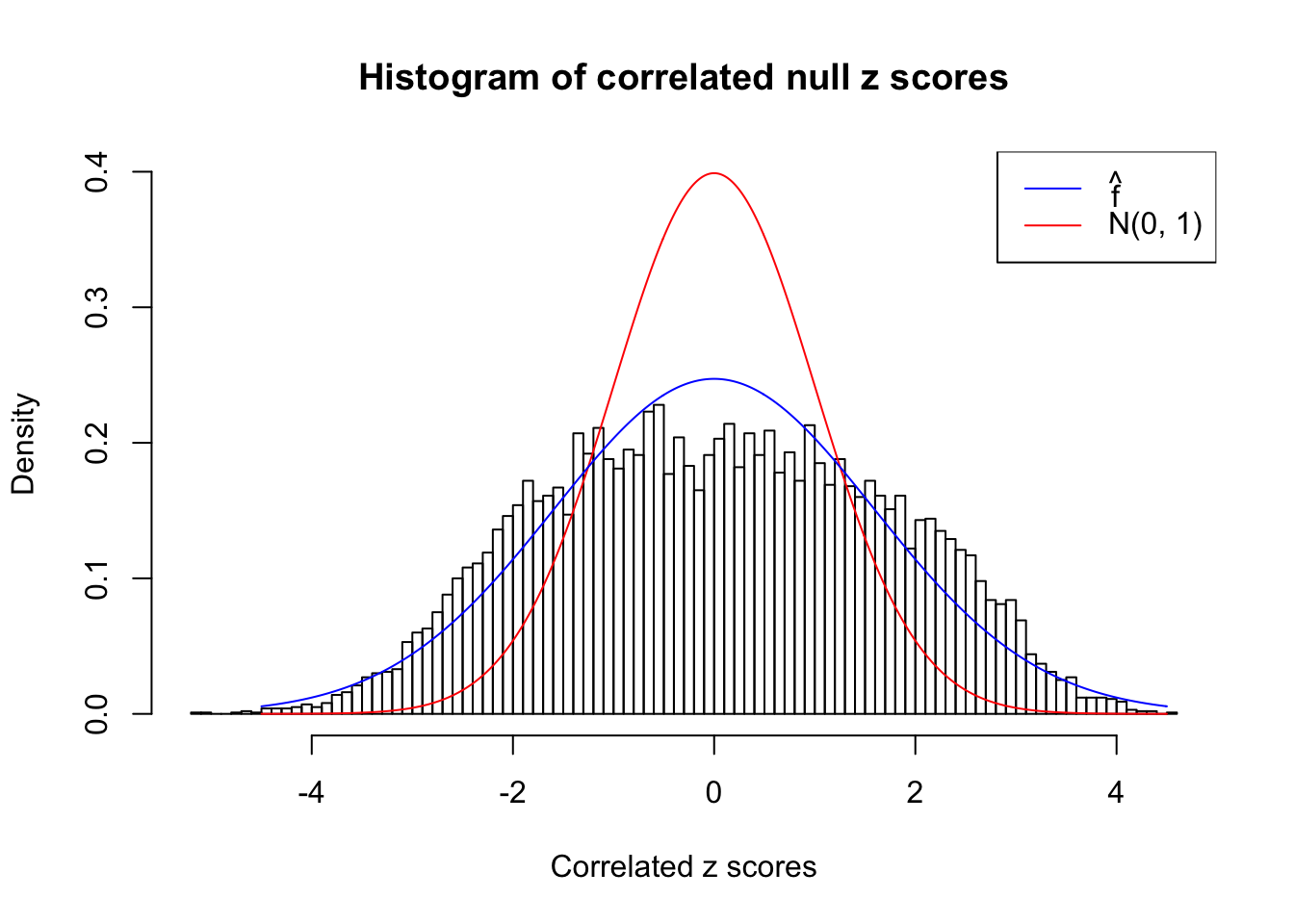
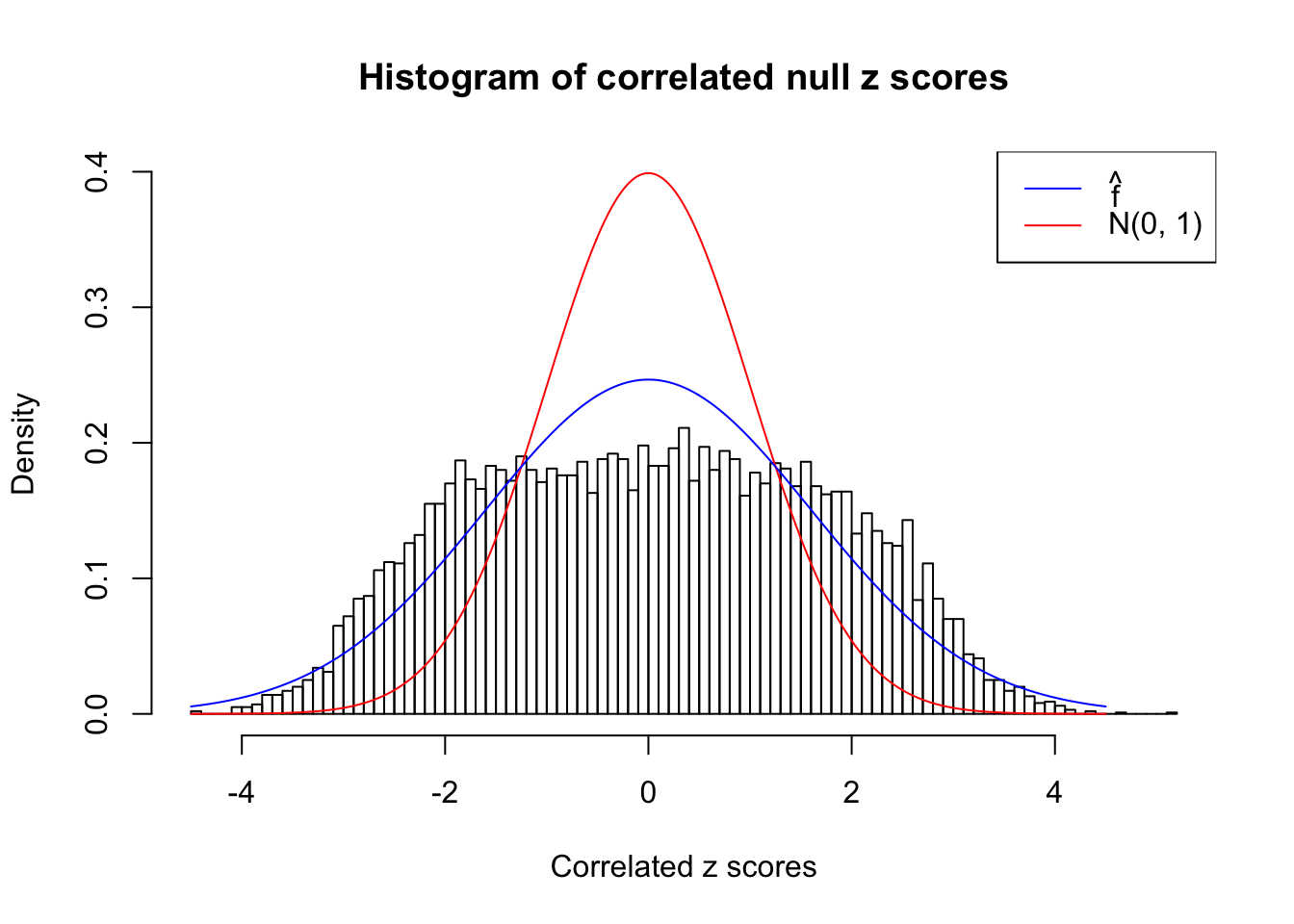
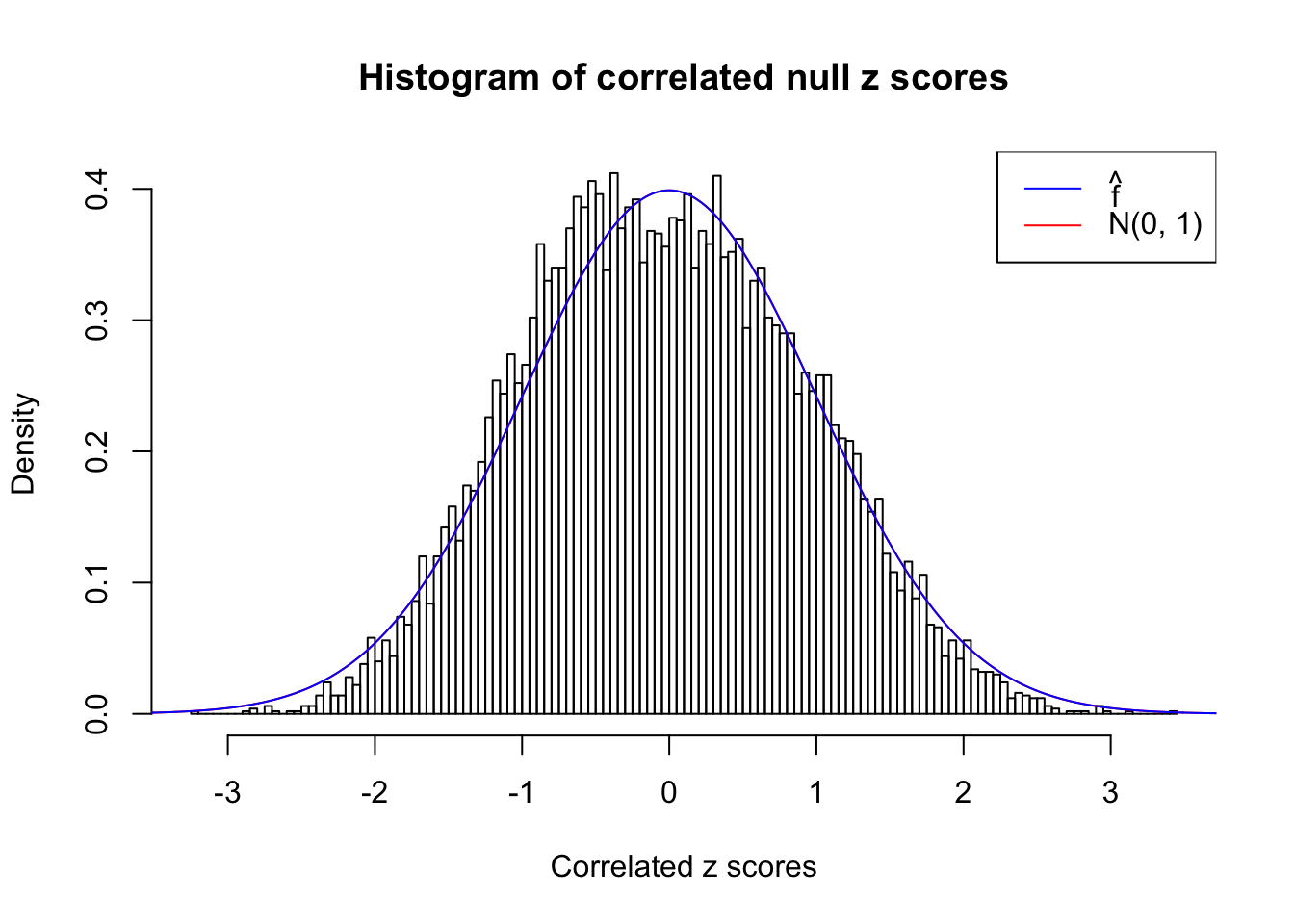
}W can also plot the estimated predictive density (in blue) on top of the histogram. As we can see, the blue line is not fitting the histogram well, as an indicator of ASH’s lack of goodness of fit to this data set.
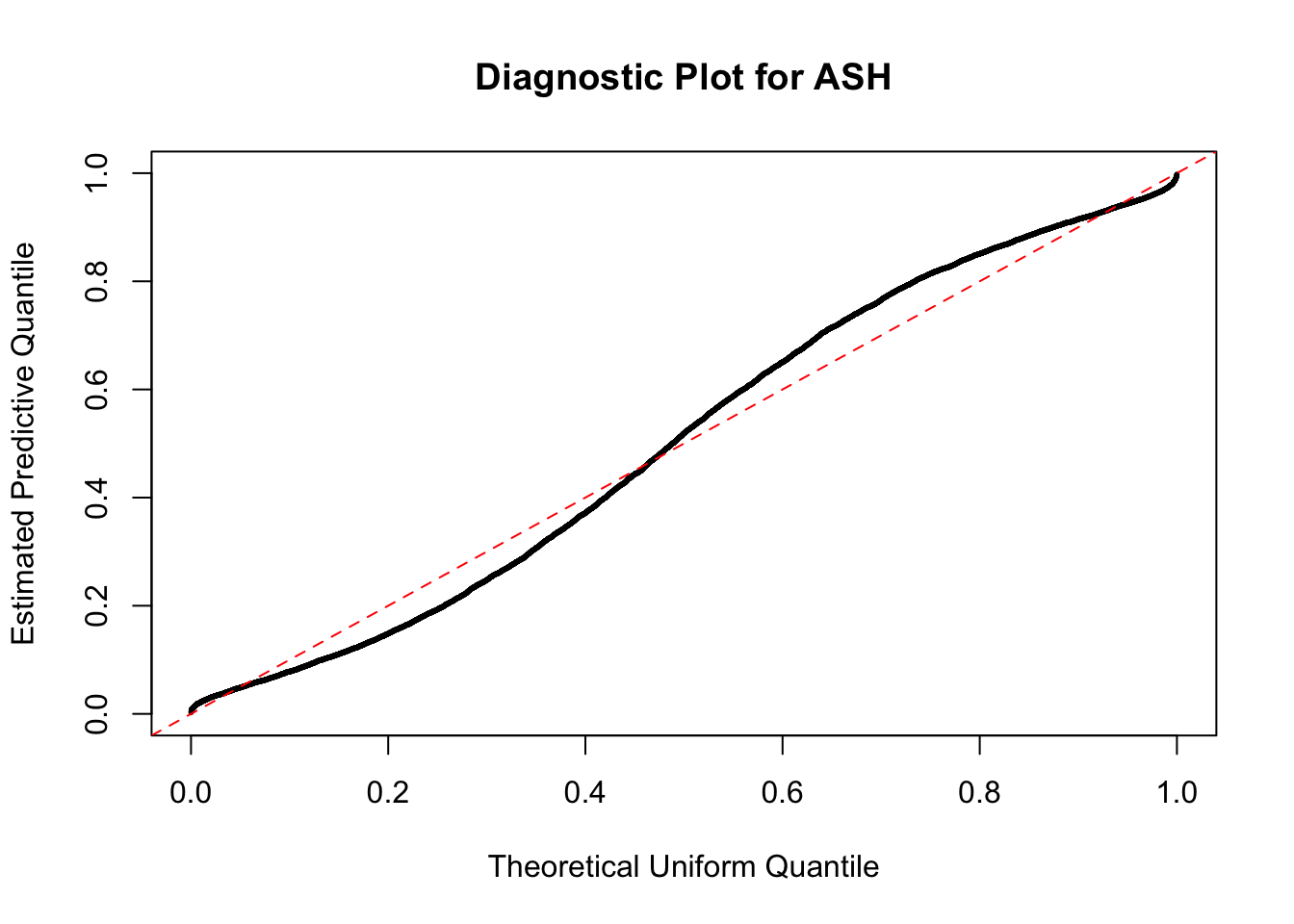
The predictive CDF of this data set should be far from \(\text{Uniform}\left[0, 1\right]\), so the diagnostic Q-Q plot should be conspicuously deviating from the \(0\)-\(1\) straight line. And we’ve also seen many points outside of the error bounds in the de-trended plot. We can also see that the two choices of error bounds don’t make too much difference.
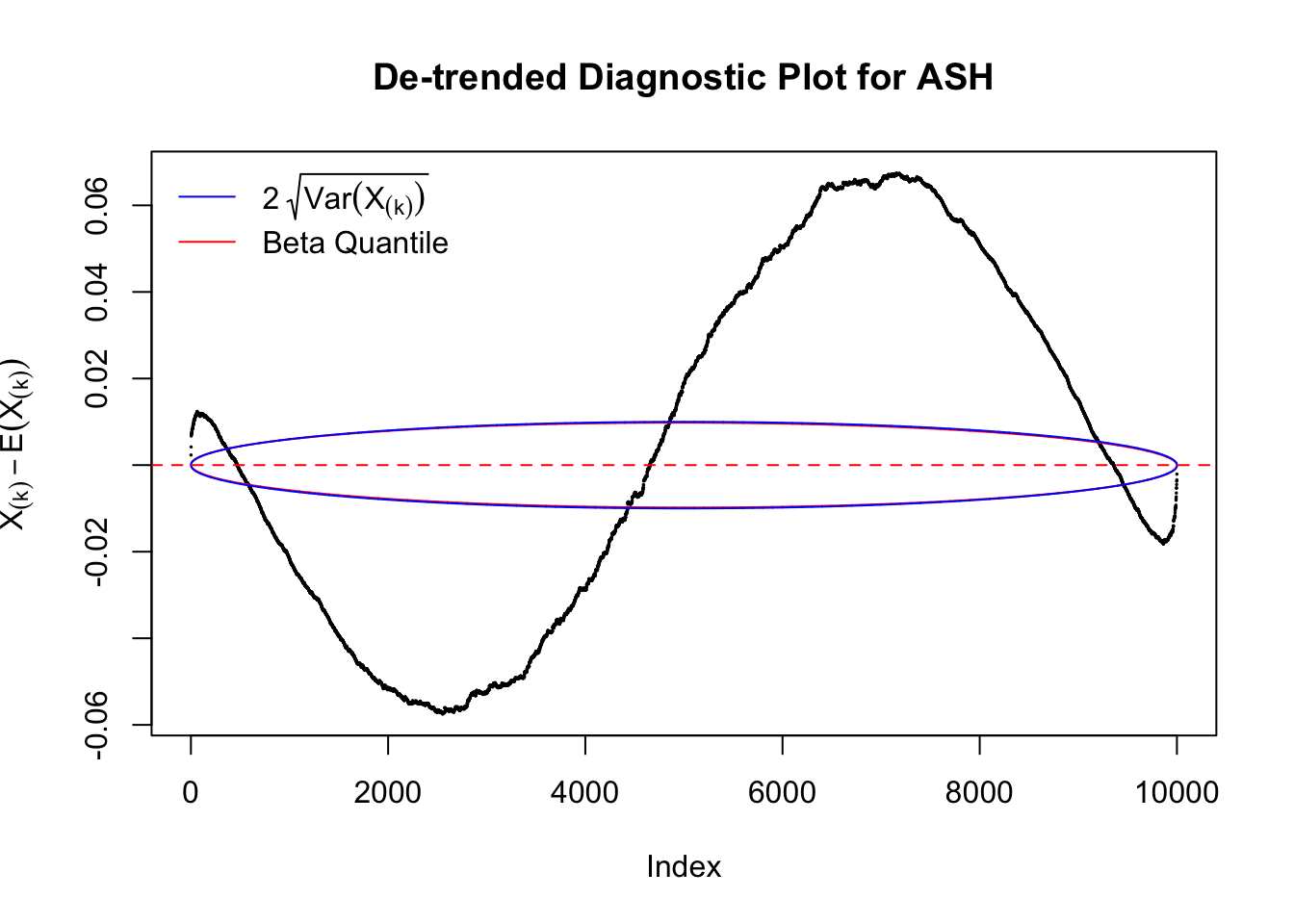
Correlated multiple comparison
However, this simple de-trended plot has drawbacks. Suppose we apply ASH to independent \(z\) scores. ASH should correctly estimate \(\hat g\) to be a point mass at \(0\) or something very close to it. Then the predictive cdf should be approximately uniformly distributed, which means we shouldn’t observe too many points outside the error bounds. However, here we do this simulation \(10\) times, and it’s more common than expected to observe points outside the bounds.
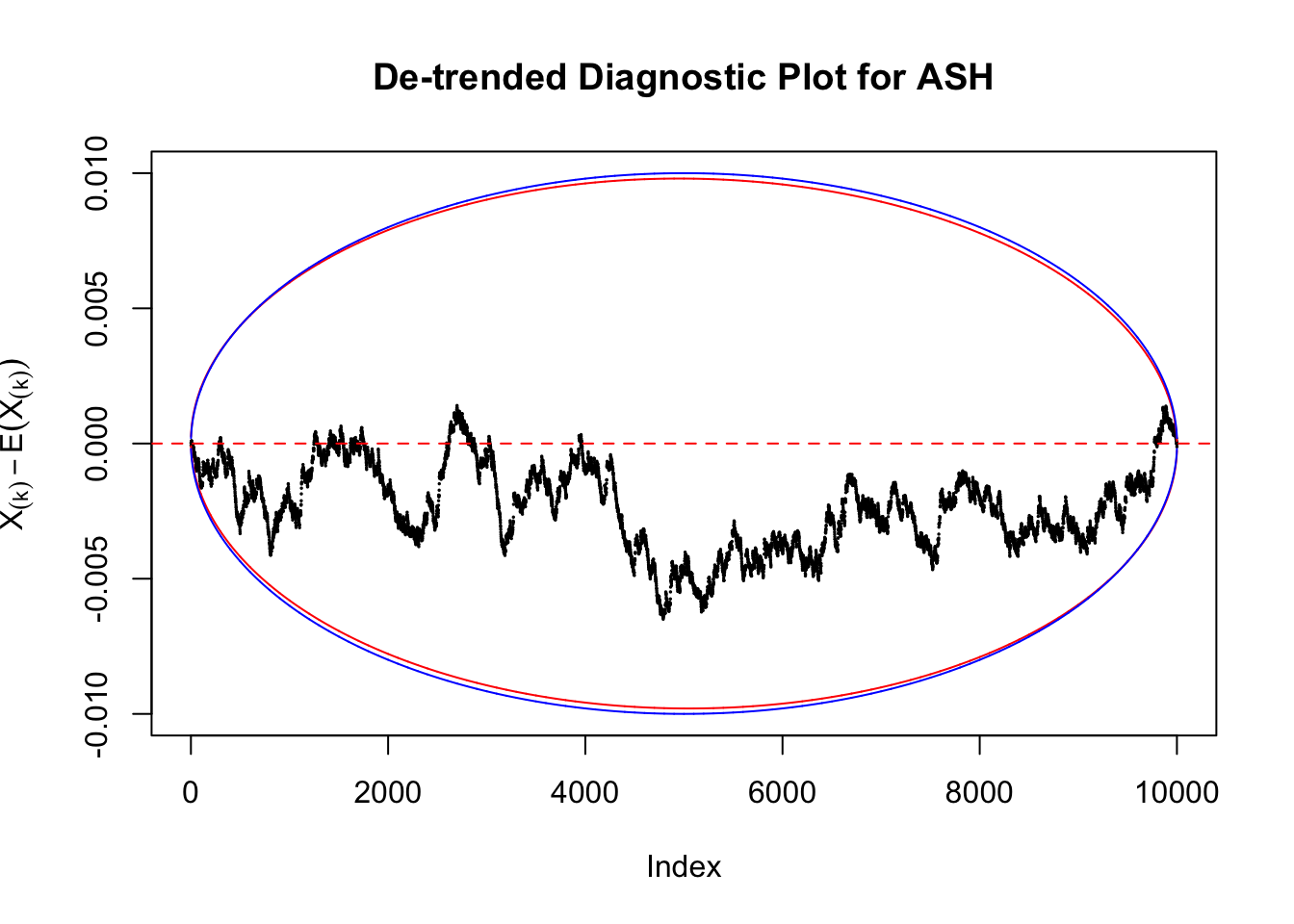
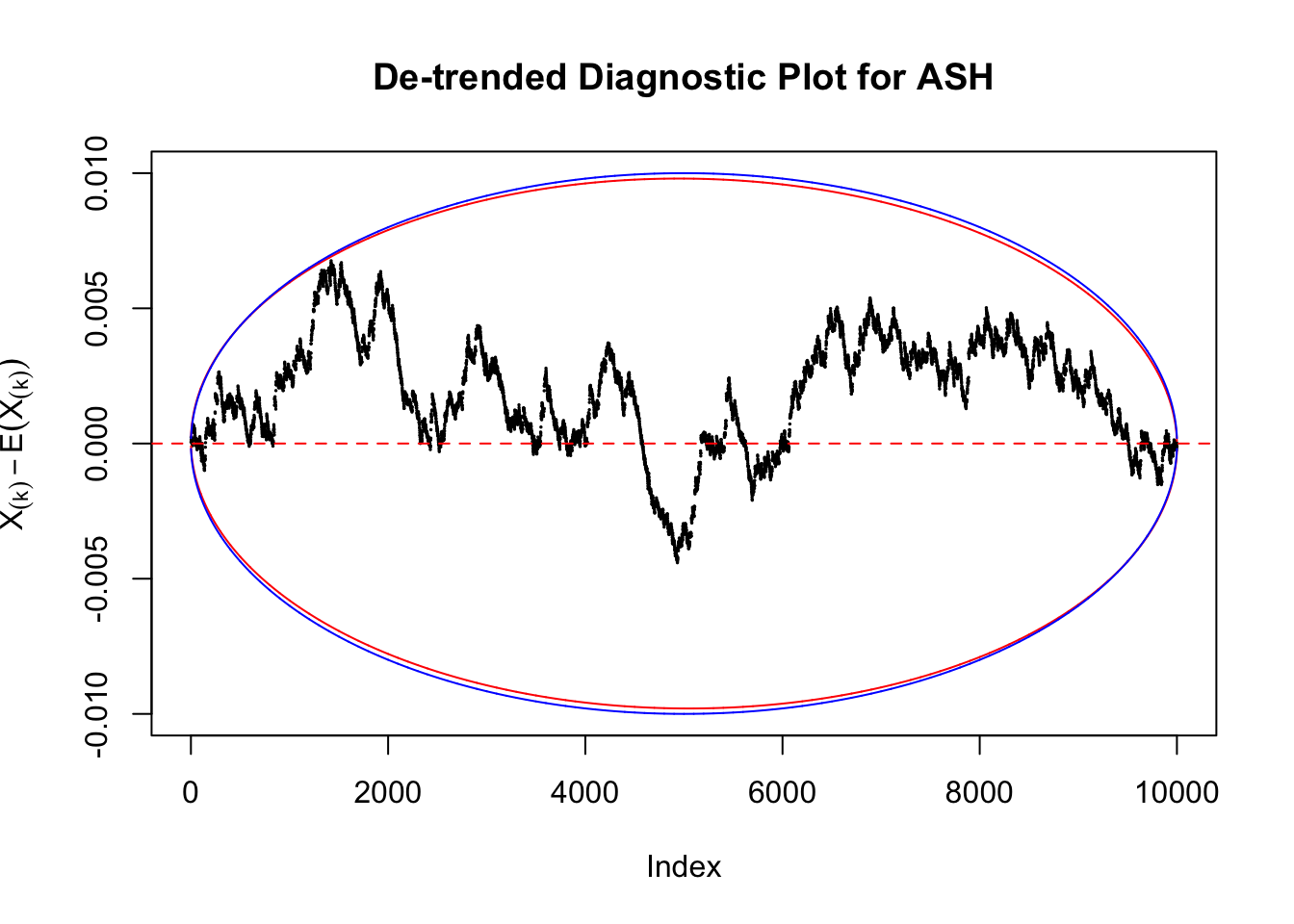
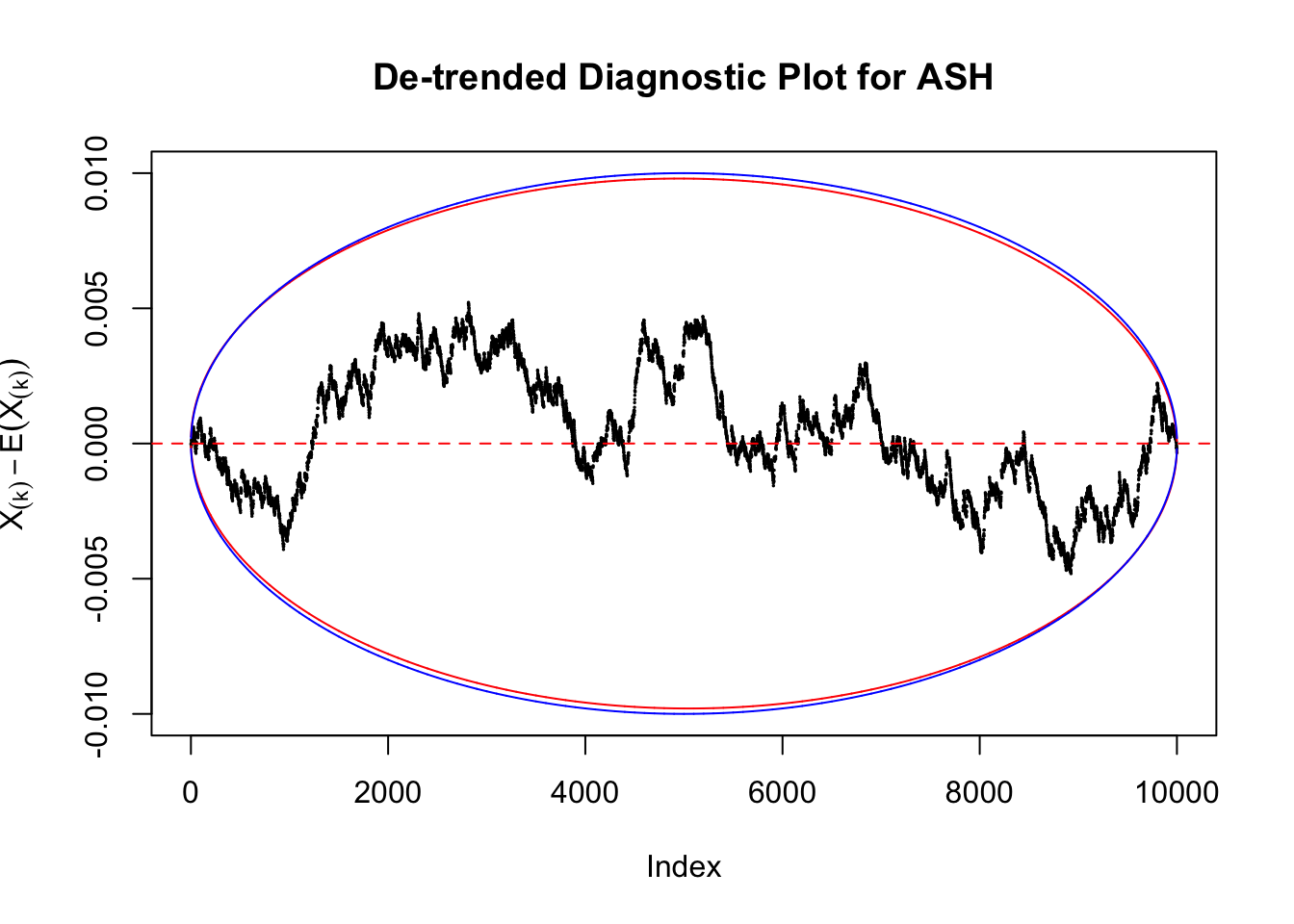
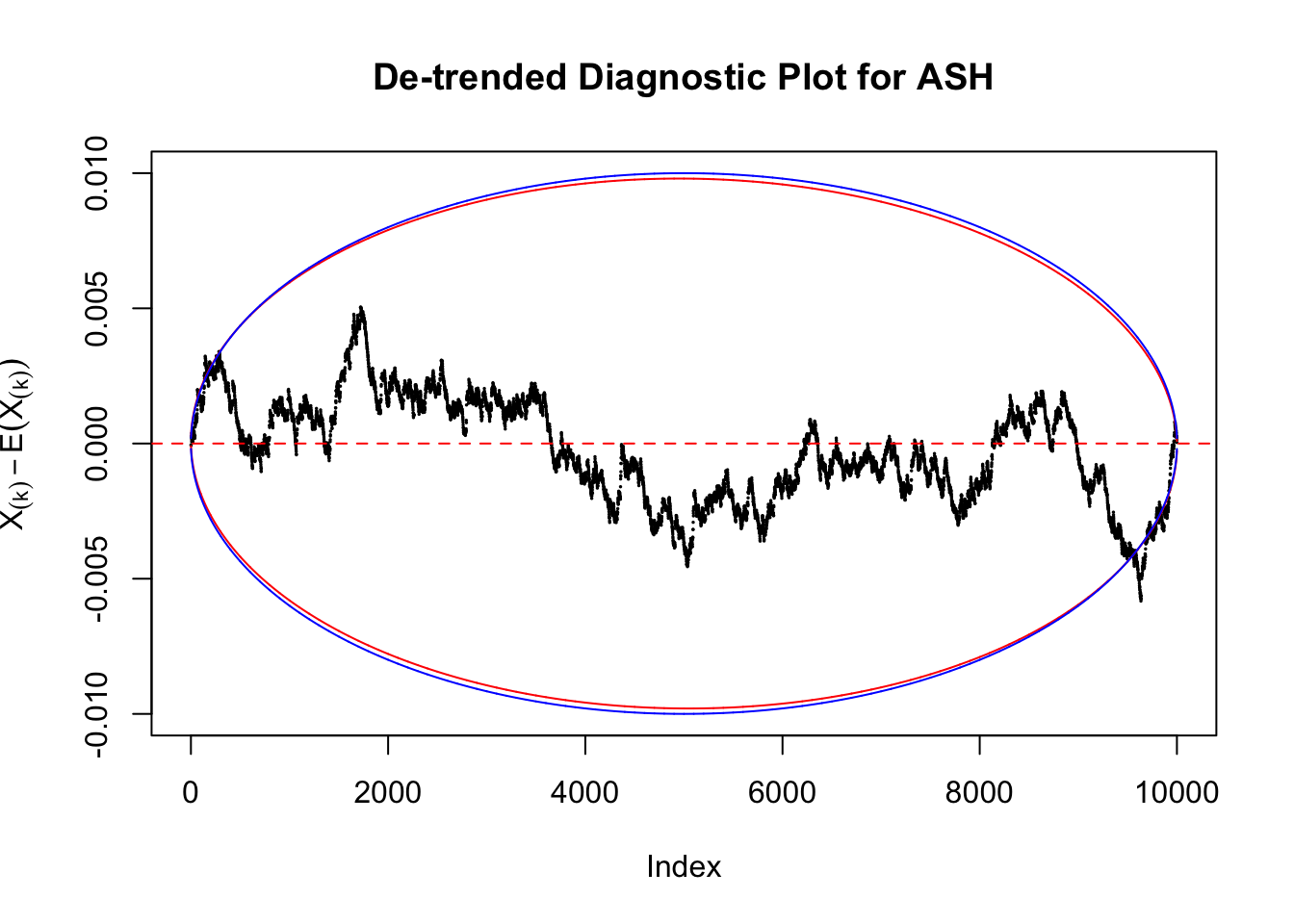
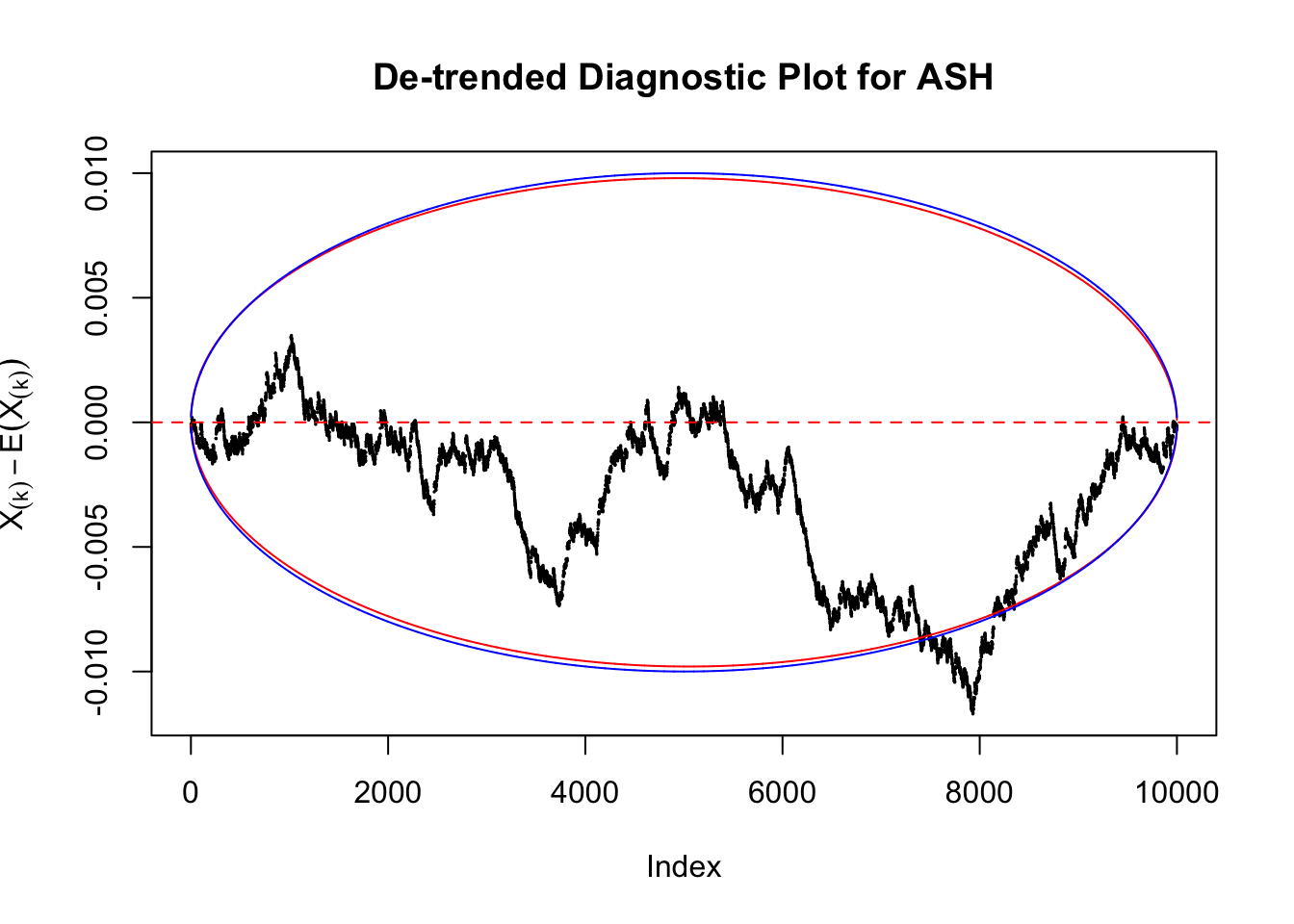
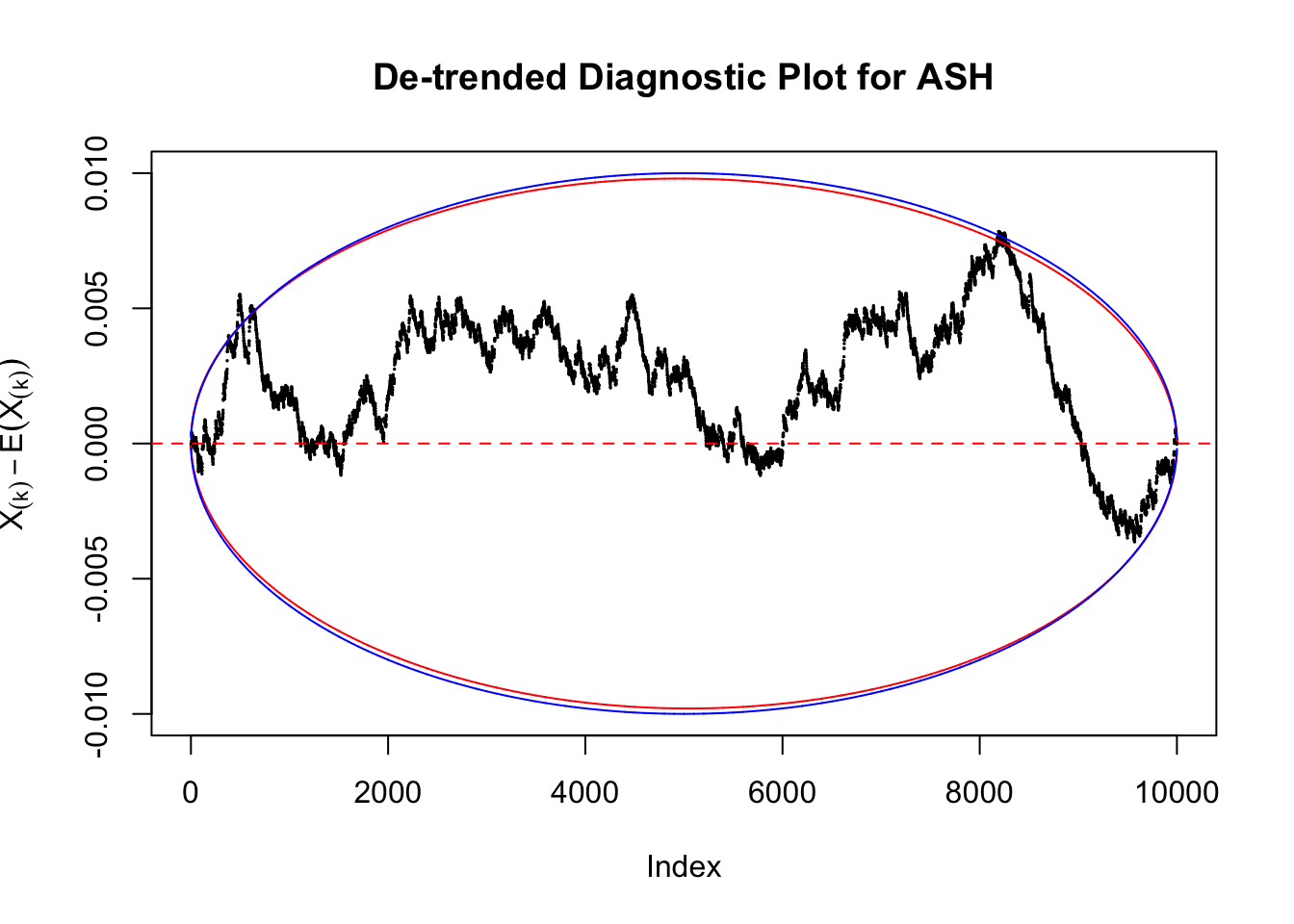
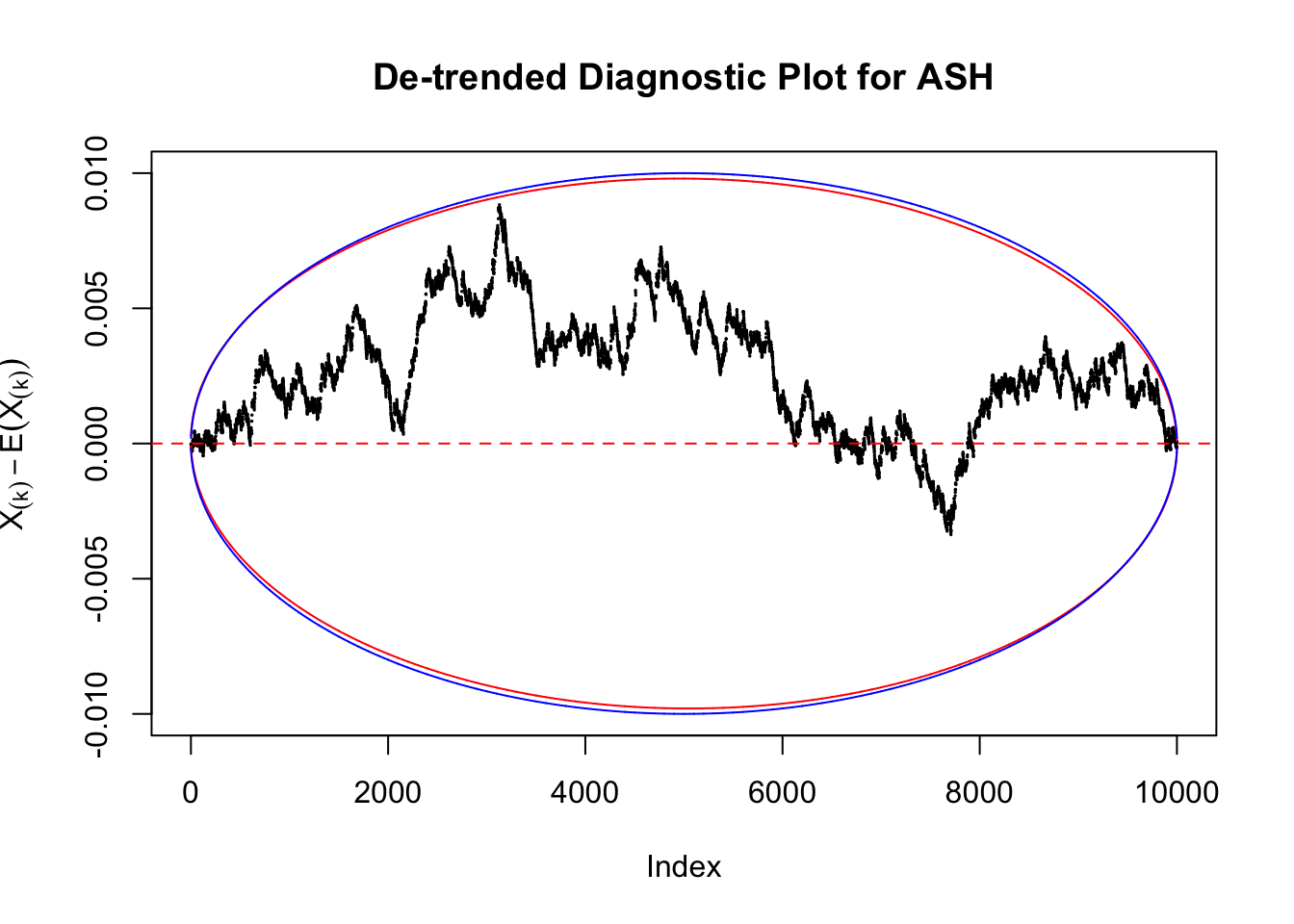
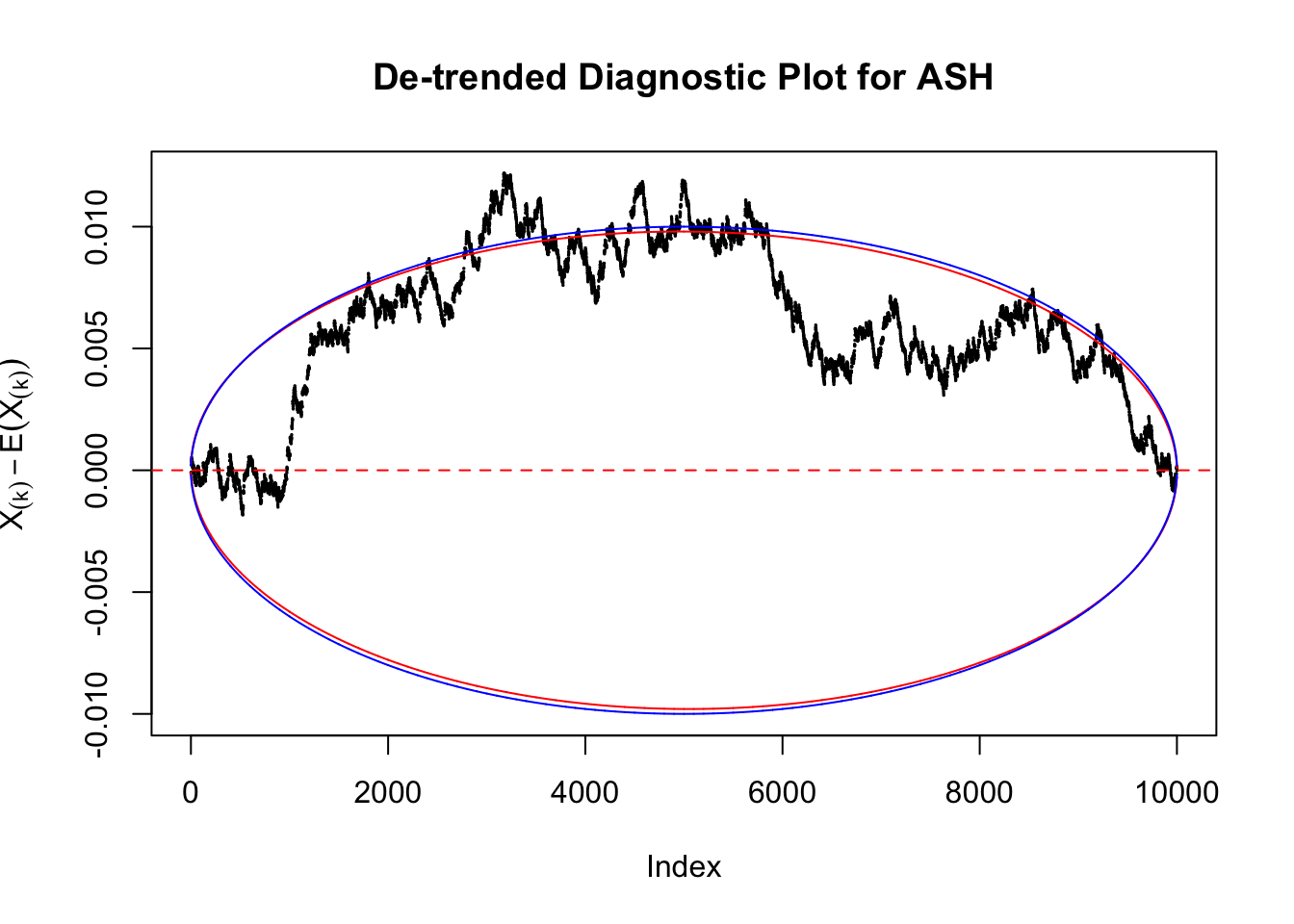
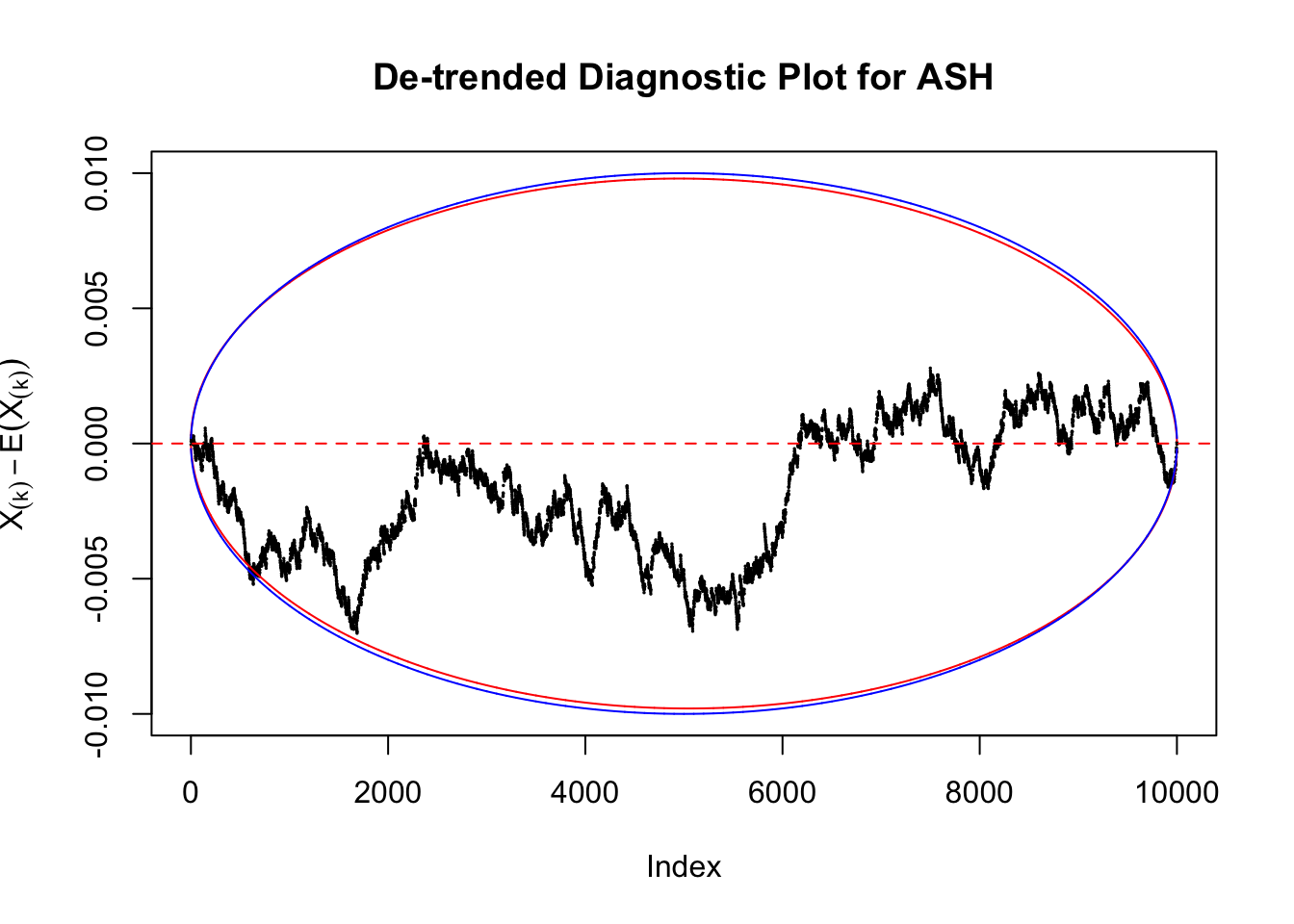
It happens because the de-trended plot has an inherent multiple testing under correlation issue. First we are comparing \(n\) sample quantiles, and then these quantiles are correlated. It may have connection with multiple testing in time series. Like in all multiple testing problems, we need to obtain a better error bound.
Here are some ideas.
Idea 1: Ignore it
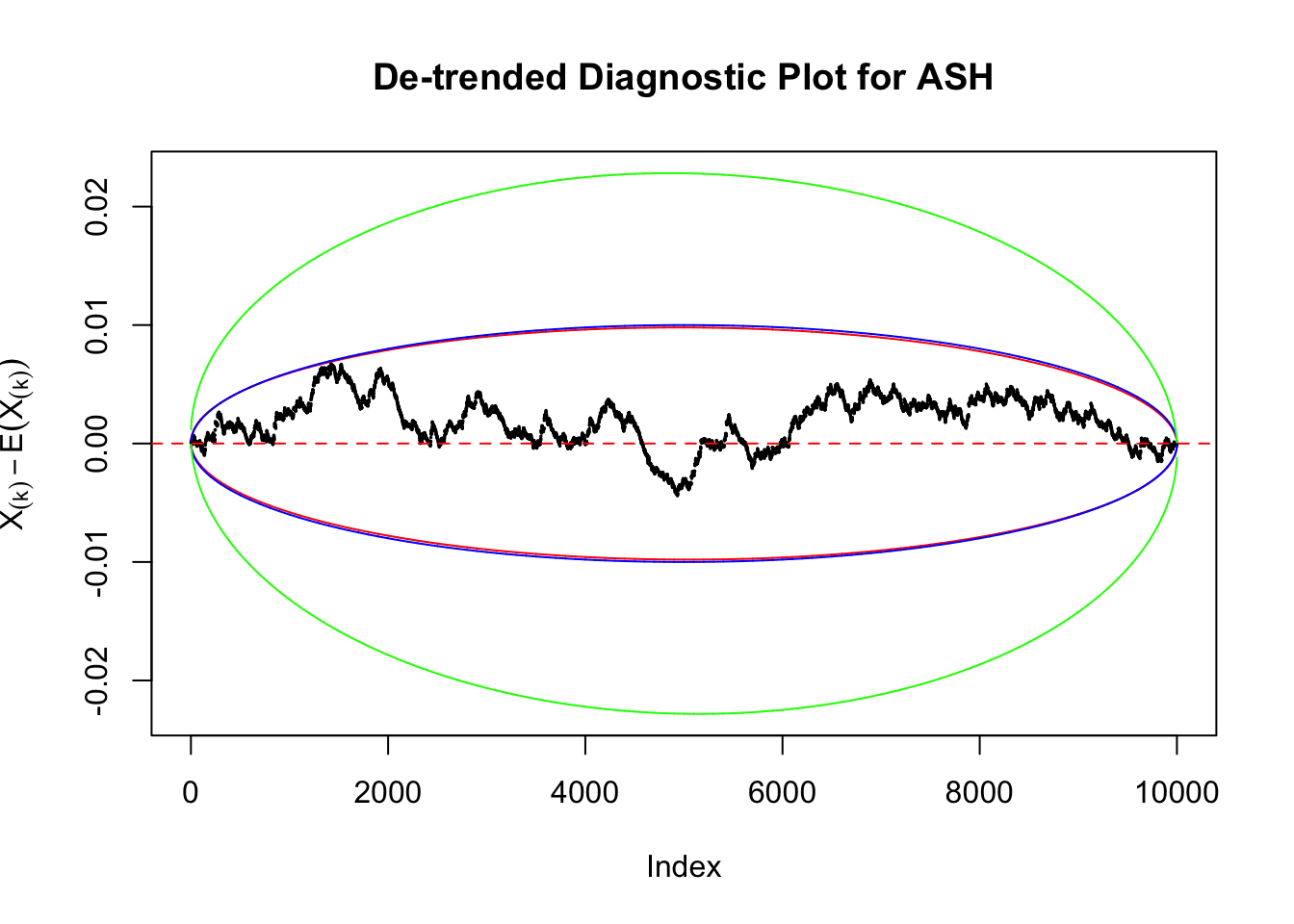
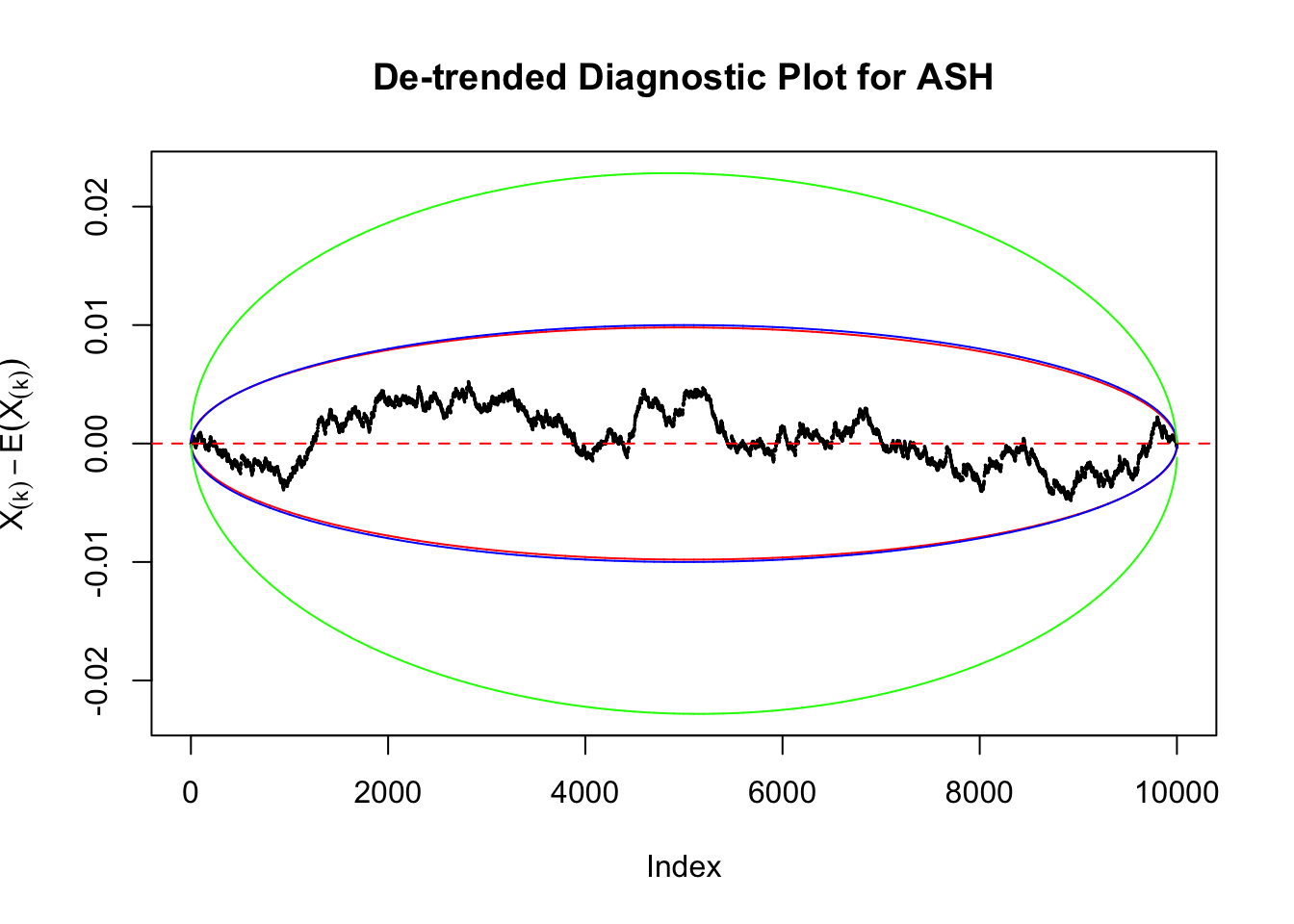
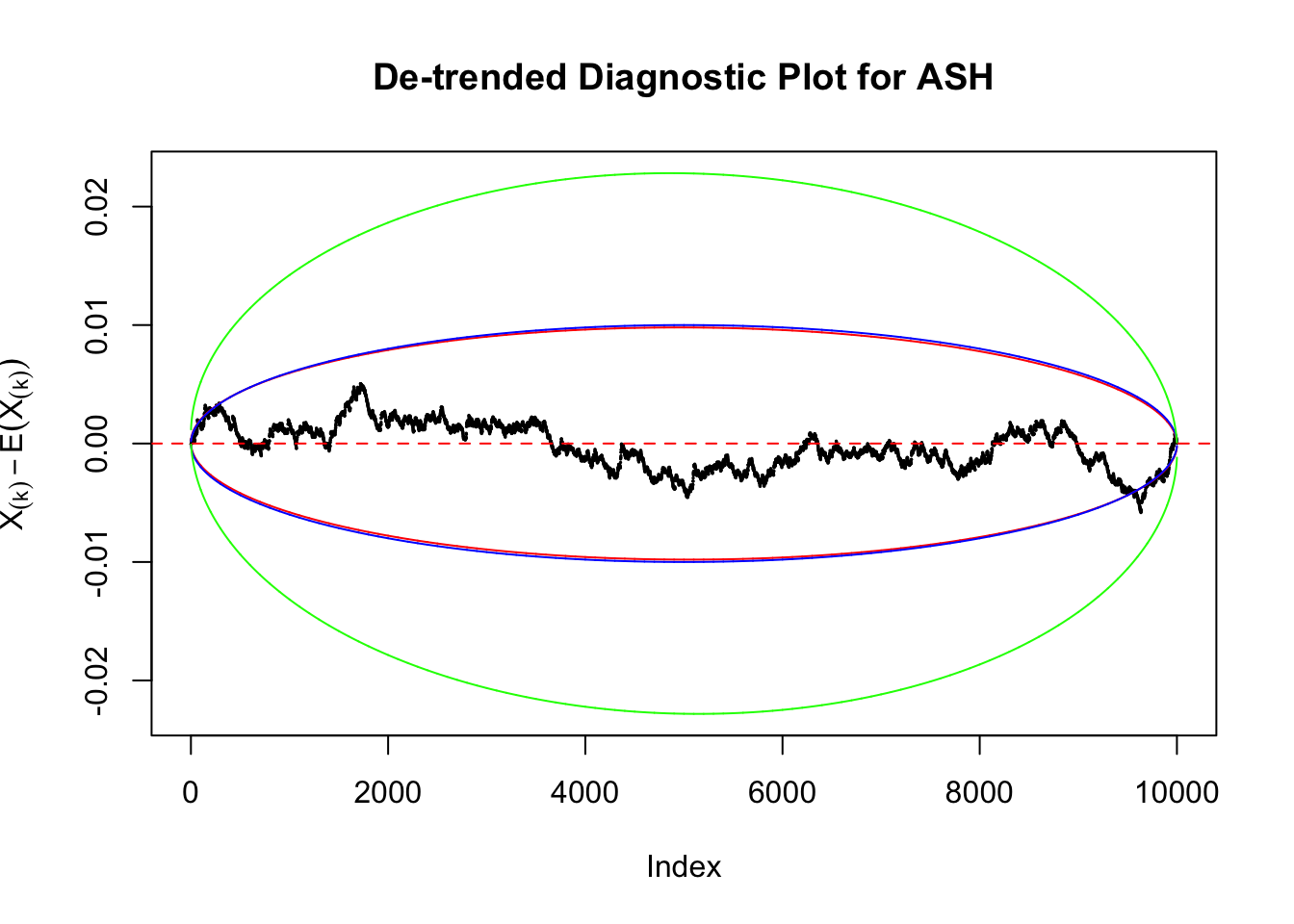
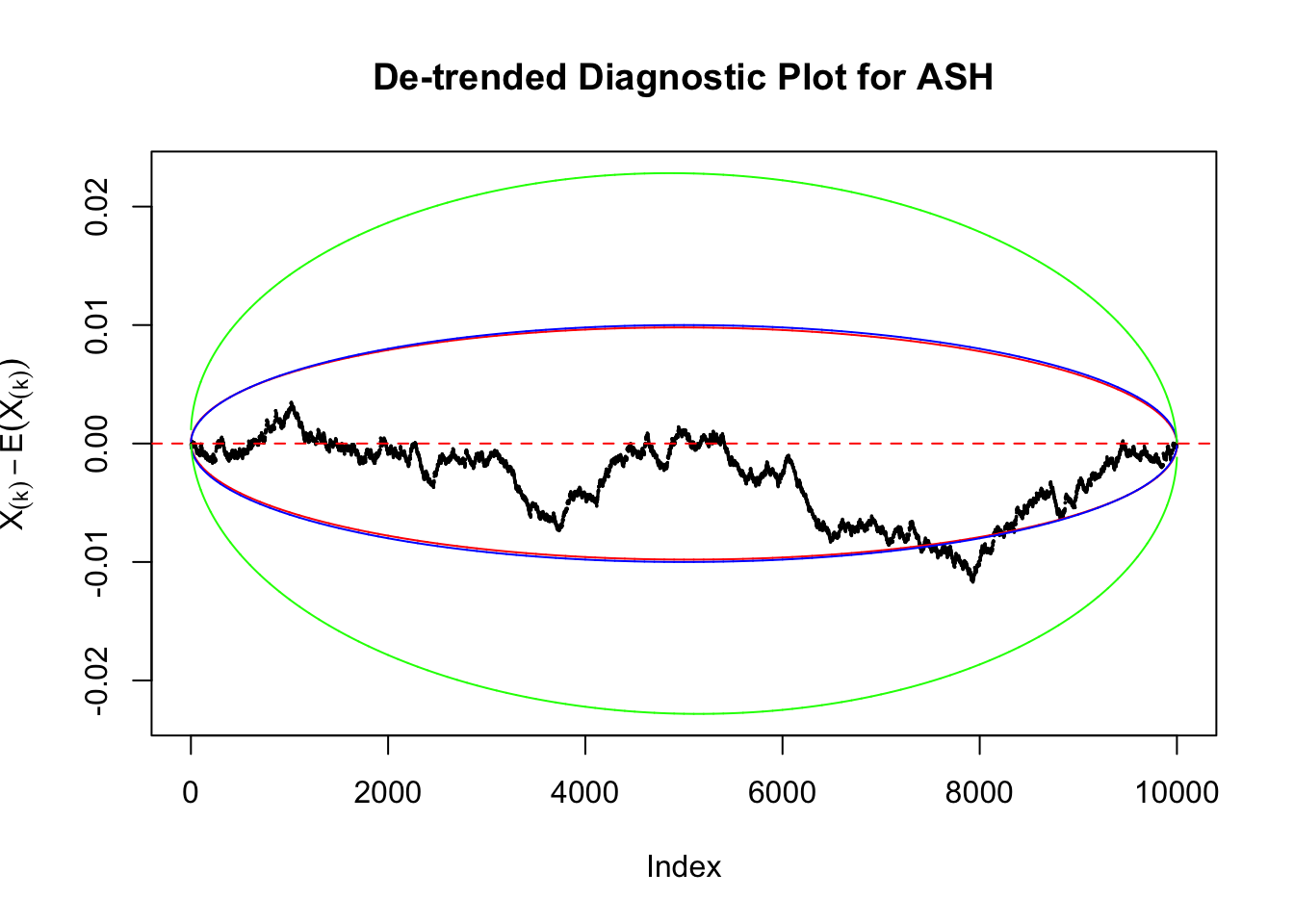
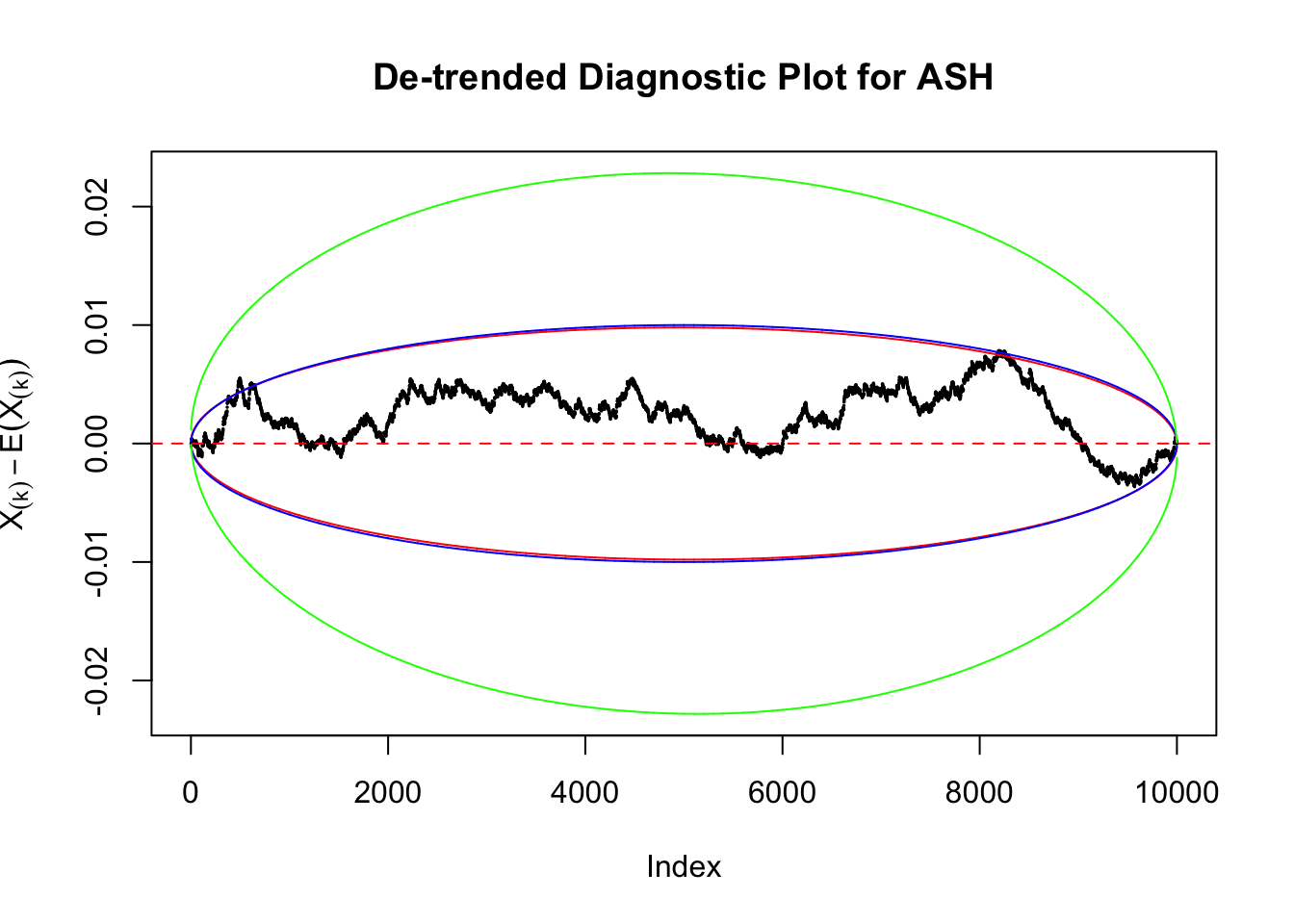
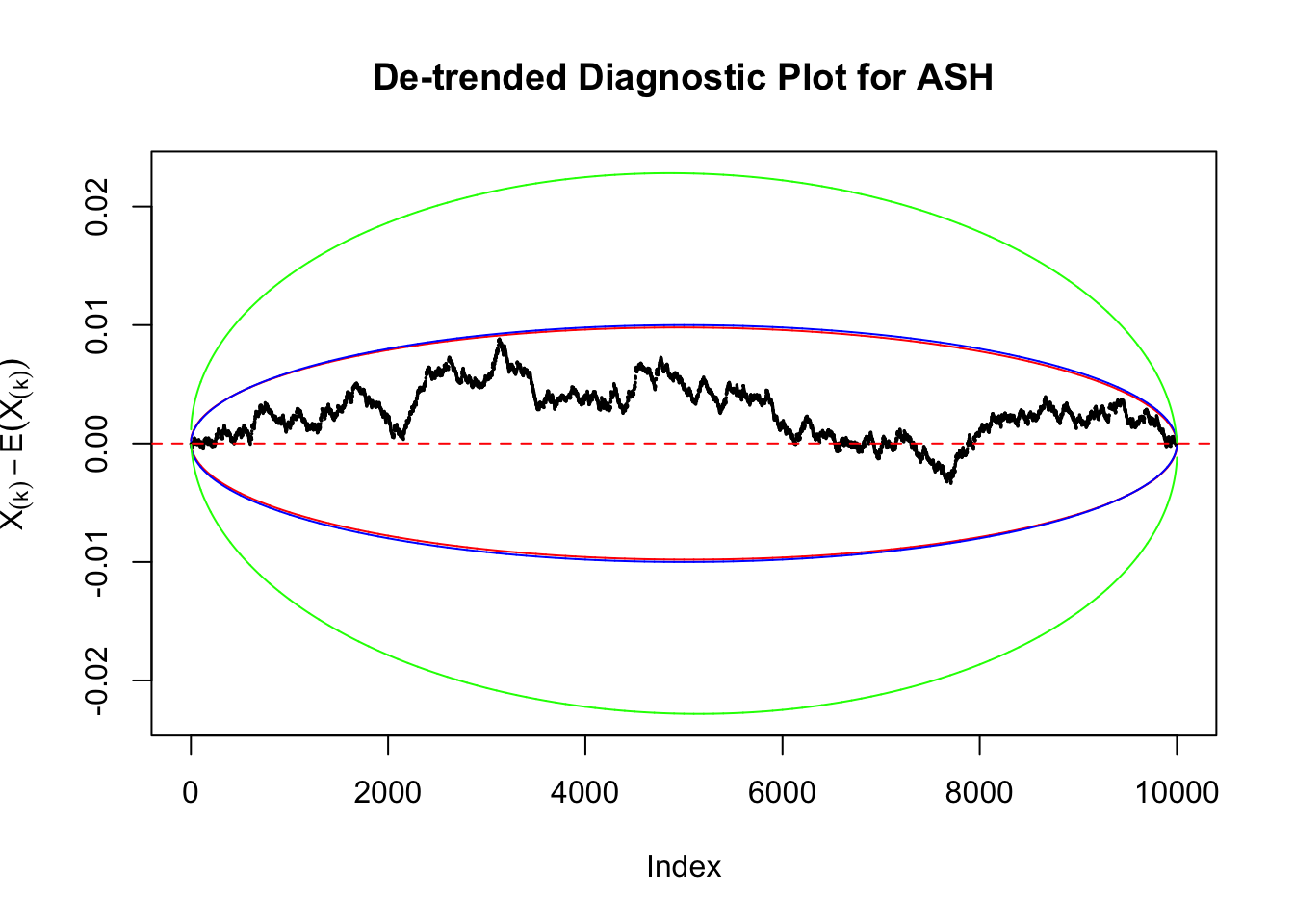
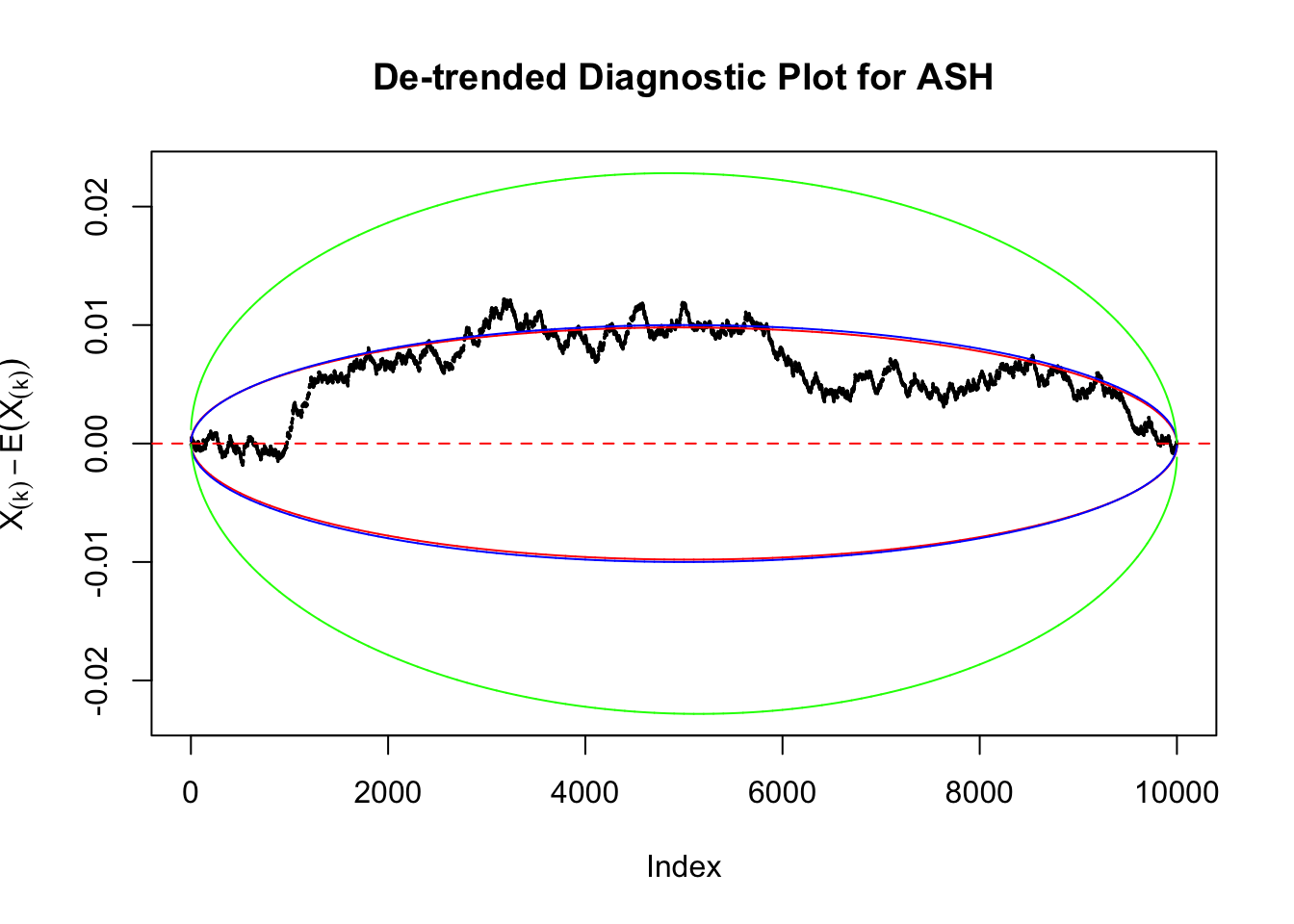
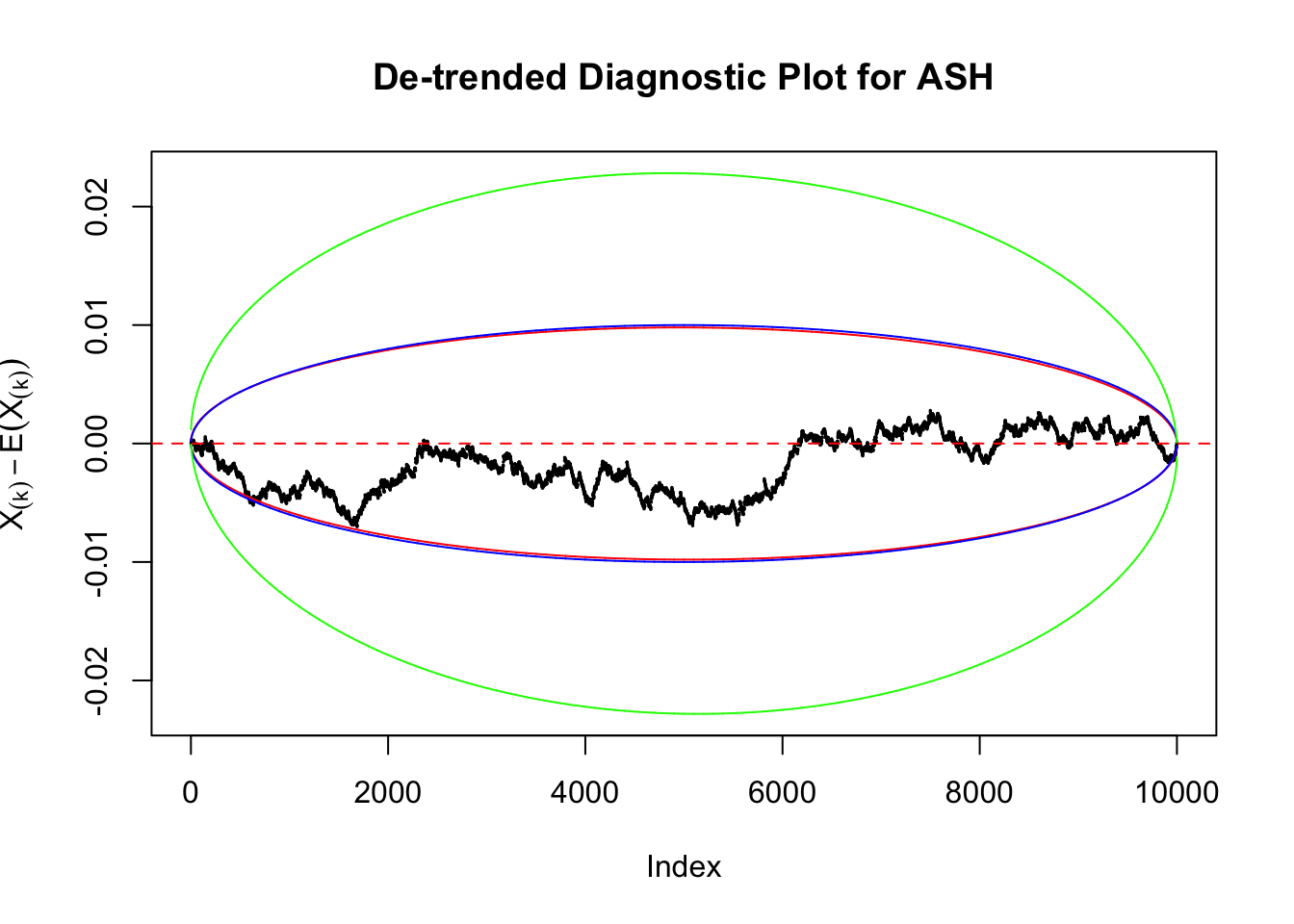
Take a look at the non-uniform plot and the ten uniform plots. It’s true that the uniform ones are not-uncommonly outside the error bounds, but they are not going too far, compared with that non-uniform one. So maybe we can just ignore the “casual” bound-crossings and accept them as uniform. Of course this will generate a lot of ambiguity for borderline cases, but borderline cases are difficult any way.
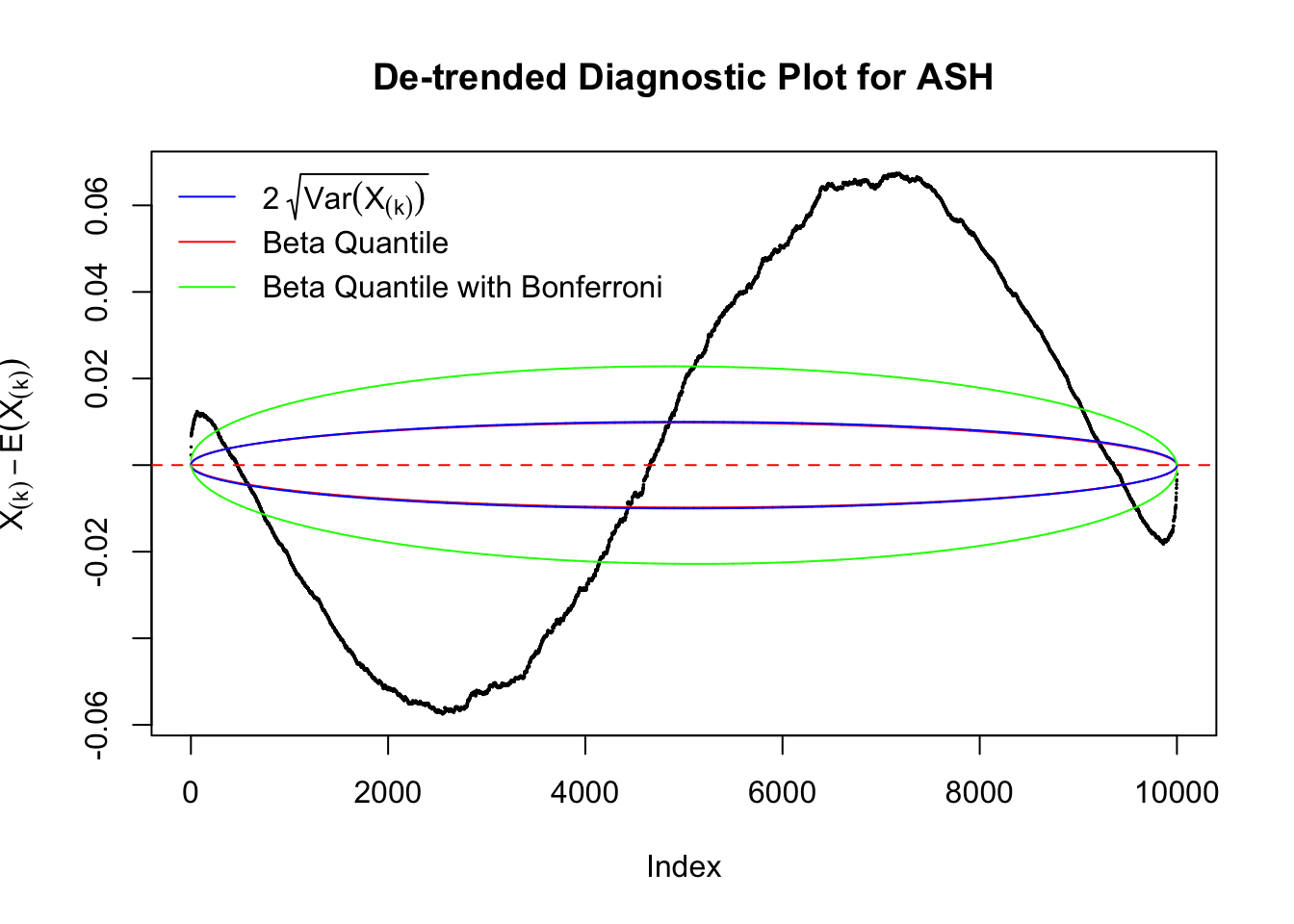
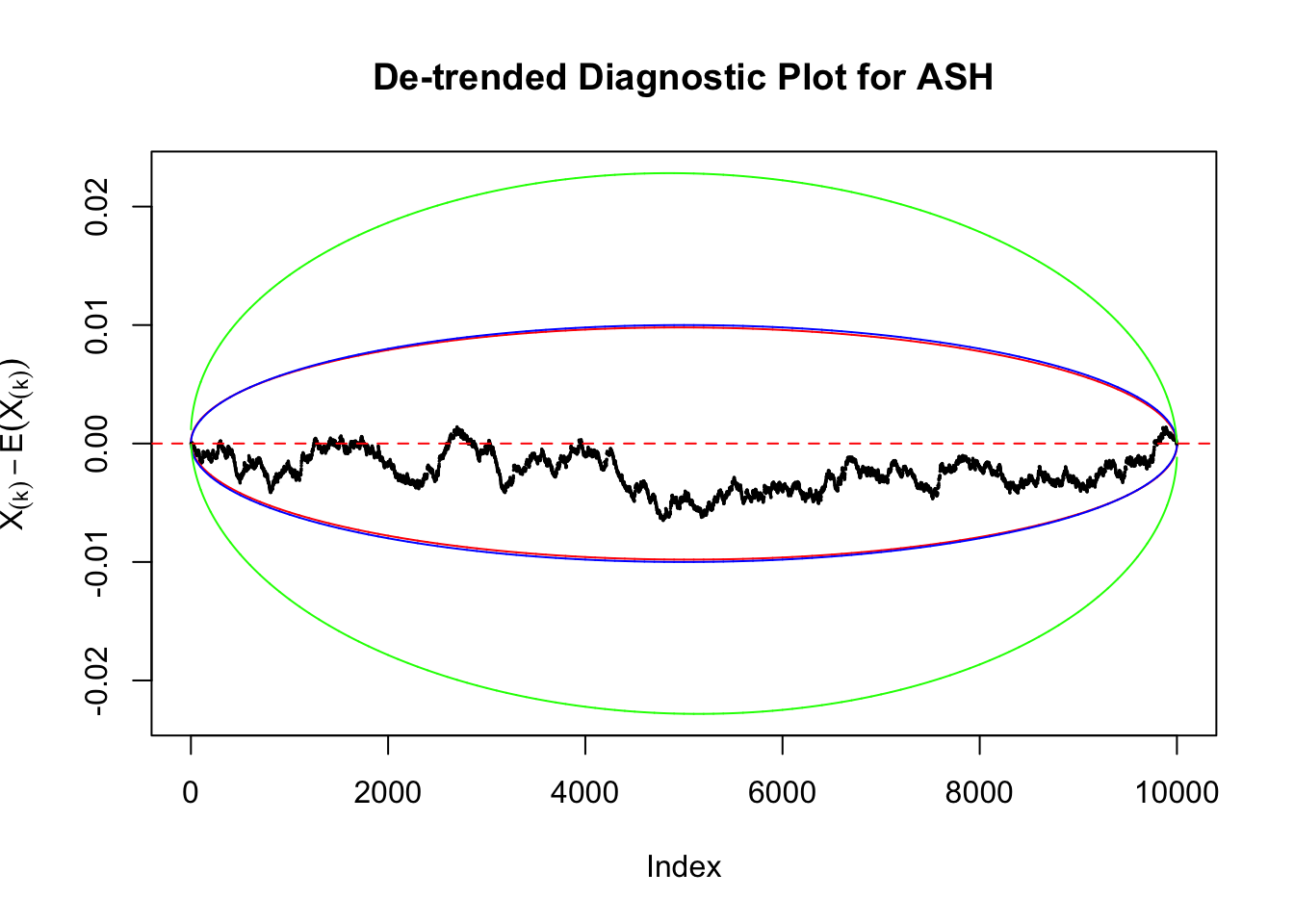
Idea 2: Bonferroni correction
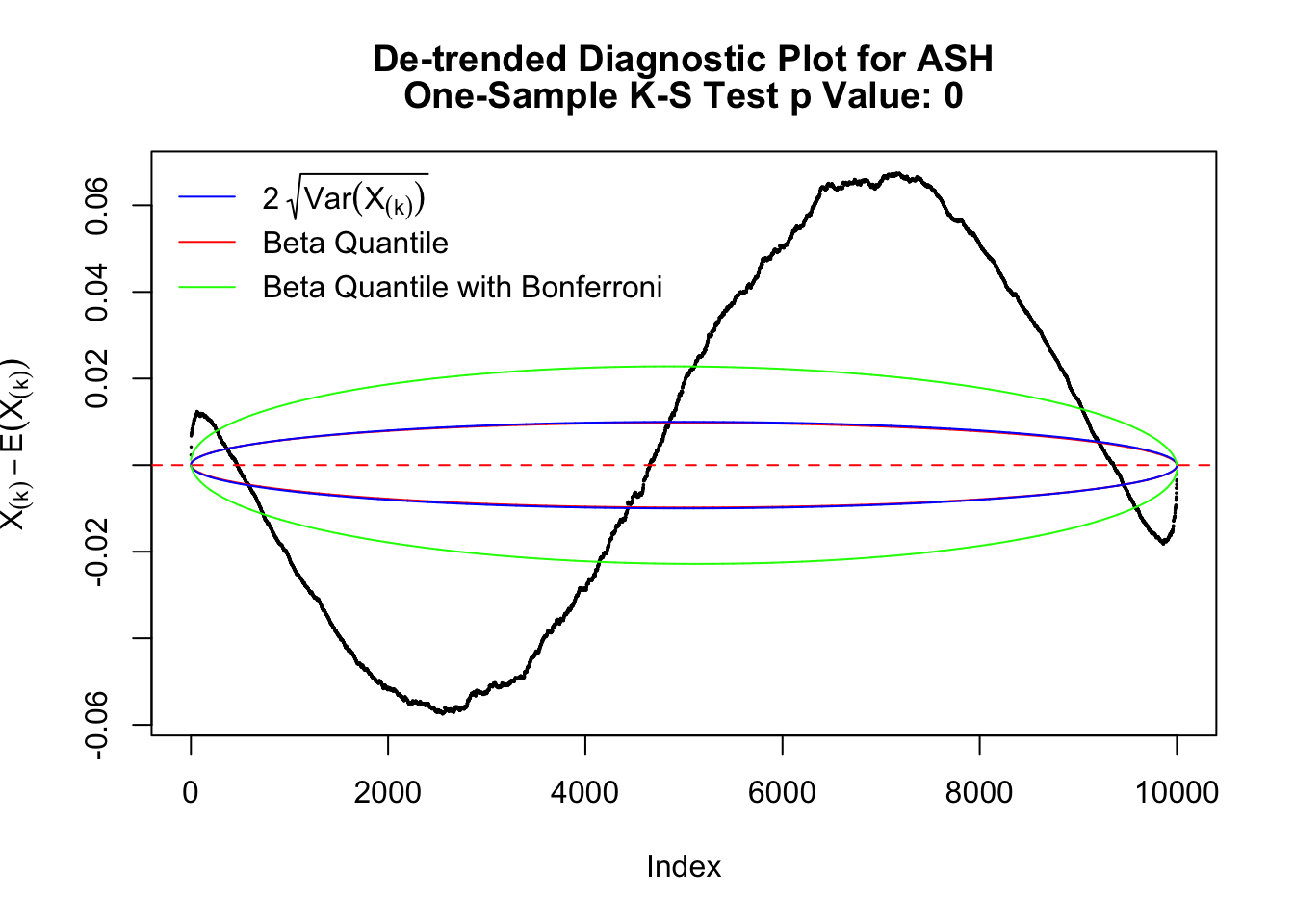
Instead of using an error bound that’s at \(\alpha\) level for each order statistic, we can use Bonferroni correction at \(\alpha / n\) level. Hopefully it will control false positives whereas still be powerful. Let’s take a look at the previously run examples.
Non-uniform
In the presence of strong non-uniformity, the de-trended plot is still well outside the Bonferroni-corrected error bounds.
Uniform
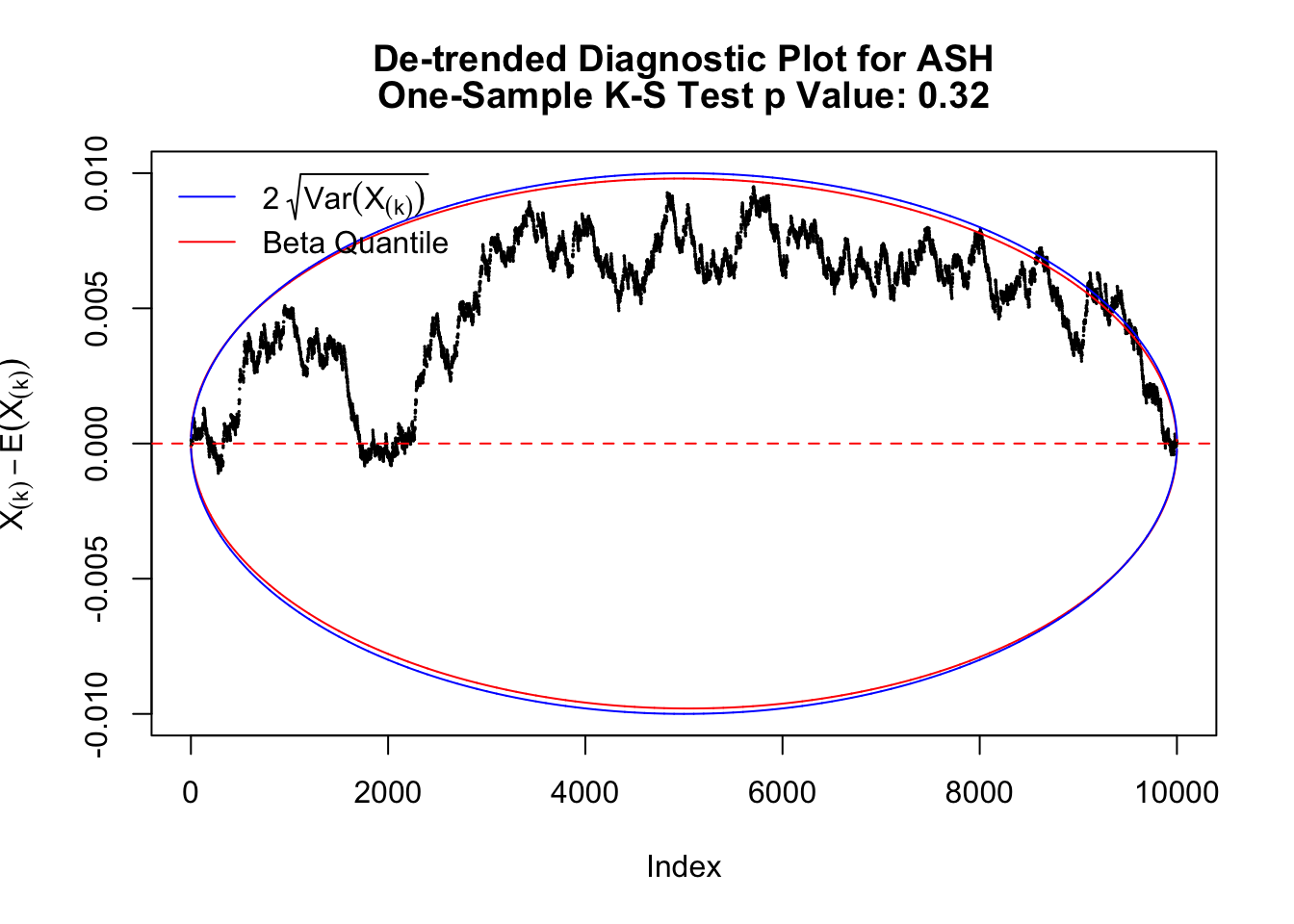
As always with Bonferroni correction, it could seem under-powered, or over-controlling the type I error.
Idea 3: Predictive density on top of histogram
As discussed above, when we have constant \(\hat s_j\equiv s\), the estimated predictive density \(\hat f = \hat g * N\left(0, s^2\right)\) is the same for all observations. Therefore, we could plot \(\hat f\left(\hat \beta_j\right)\) on top of the histogram of all \(\hat \beta_j\) to see if ASH fits the data and estimates the prior \(g\) well.
We are selecting four data sets with \(N(0, 1)\) \(z\) scores distorted by correlation. The first two are inflated, and the latter two mildly deflated. ASH has a hard time handling both cases, and the fitted predictive density curves can show that.
Idea 4: Kolmogorov-Smirnov (K-S) test
As explained in Wikipedia,
In statistics, the Kolmogorov–Smirnov test (K–S test or KS test) is a nonparametric test of the equality of continuous, one-dimensional probability distributions that can be used to compare a sample with a reference probability distribution (one-sample K–S test), or to compare two samples (two-sample K–S test). It is named after Andrey Kolmogorov and Nikolai Smirnov.
The K-S test gives a \(p\)-value, which can be displayed alongside all kinds of diagnostic plots mentioned above, as below.
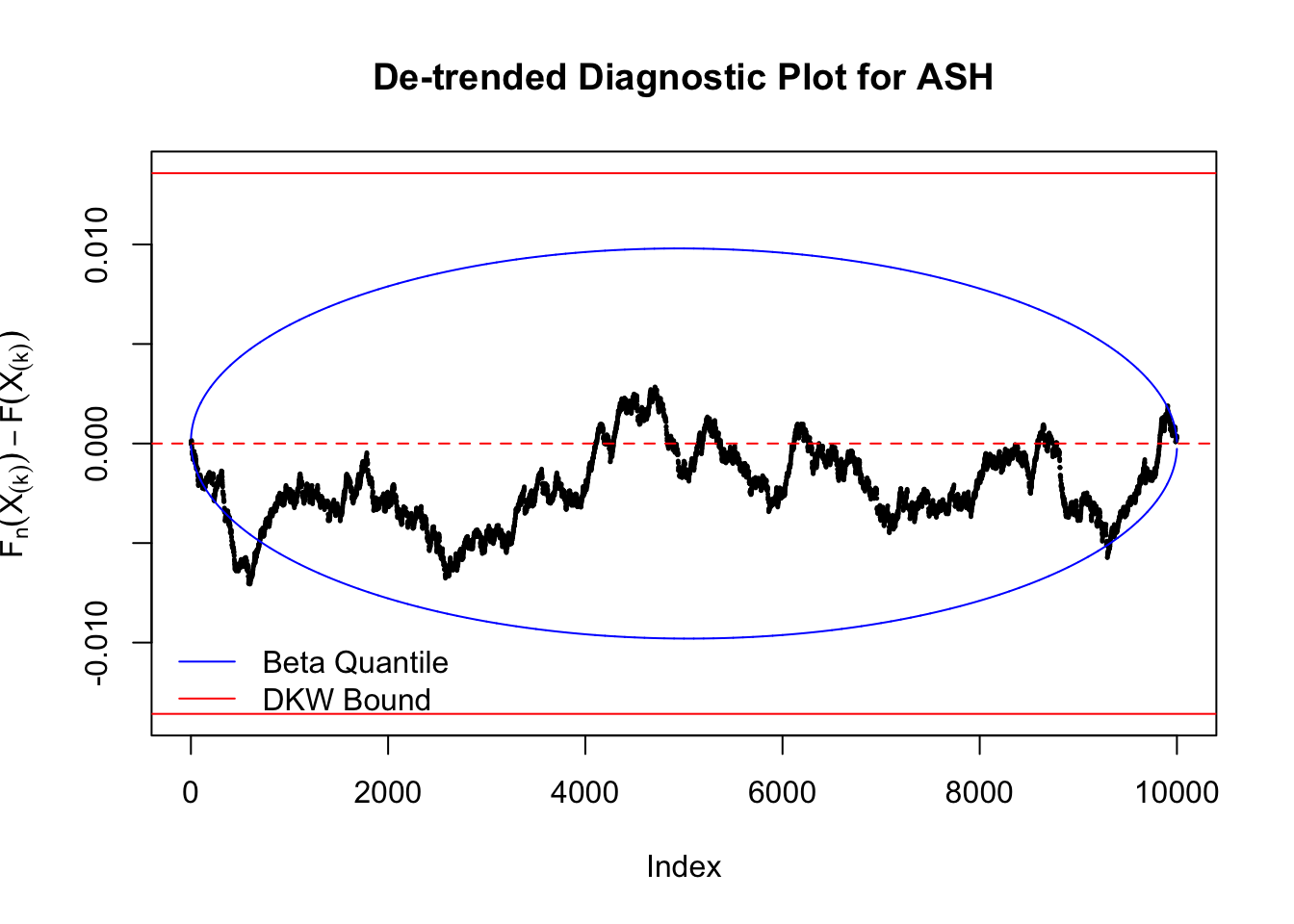
Idea 5: Empirical CDF and DKW inequality
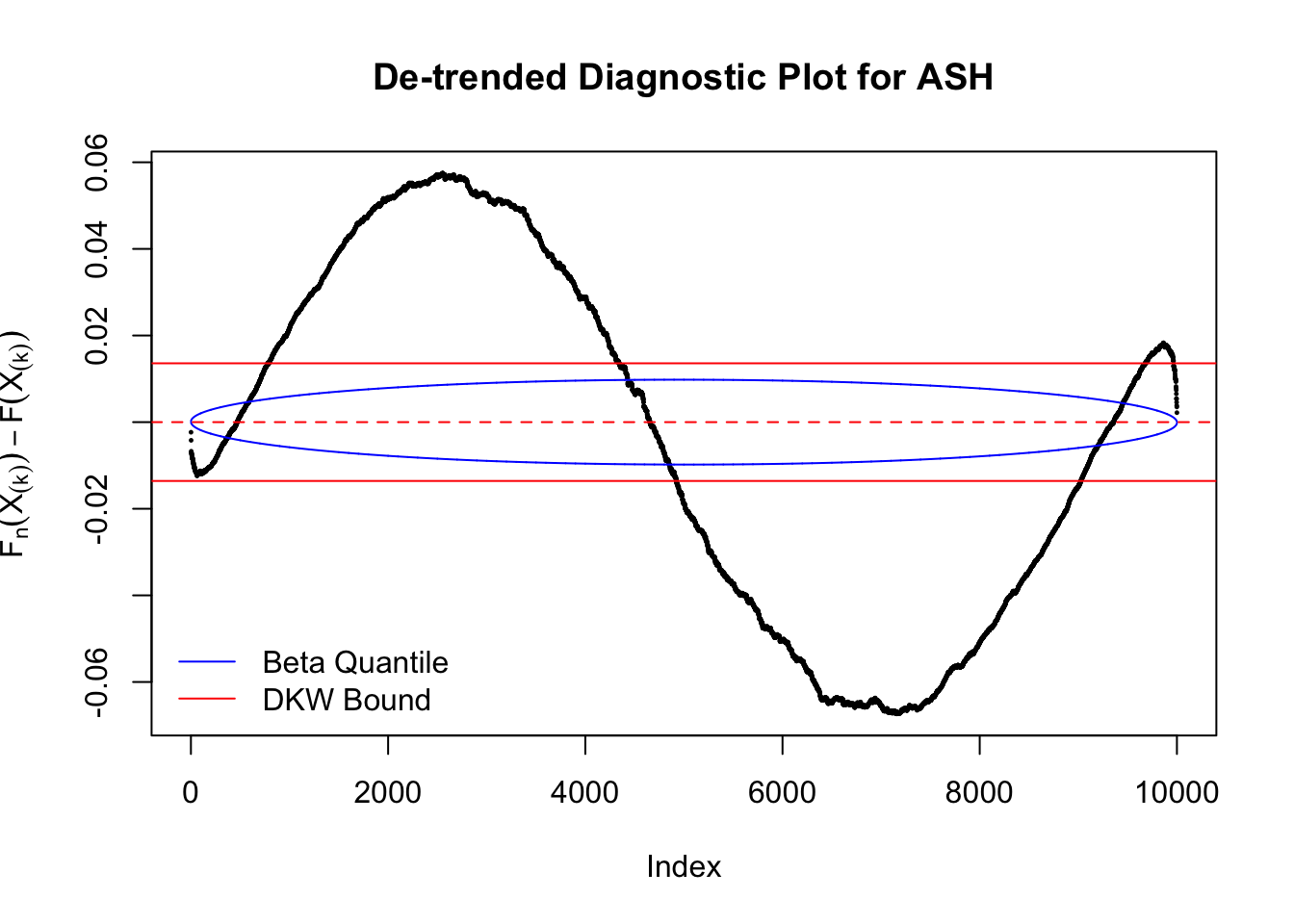
The K-S test is related to the DKW inequality for the empirical CDF. Let \(X_1, \ldots, X_n\) be \(n\) iid samples from \(F\). Let \(F_n\) denote the empirical cumulative distribution function estimated from them. Then
\[ \Pr\left(\sup\limits_{x\in\mathbb{R}}\left|F_n\left(x\right) - F\left(x\right)\right| > \epsilon\right) \leq 2e^{-2n\epsilon^2} \ . \]
Therefore, we can set \(\epsilon\) so that \(\alpha = 2e^{-2n\epsilon^2}\), and plot \(F_n\left(X_{(k)}\right) - F\left(X_{(k)}\right) = \frac kn - X_{(k)}\) against \(\pm\epsilon\). Note that in this case we are plotting \(F_n\left(X_{(k)}\right) - F\left(X_{(k)}\right)\), not \(X_{(k)} - E\left[X_{(k)}\right]\), but under uniform they are very close, with no practical difference.
Session information
sessionInfo()R version 3.4.3 (2017-11-30)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS High Sierra 10.13.2
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.4/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.4/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] compiler_3.4.3 backports_1.1.2 magrittr_1.5 rprojroot_1.3-1
[5] tools_3.4.3 htmltools_0.3.6 yaml_2.1.16 Rcpp_0.12.14
[9] stringi_1.1.6 rmarkdown_1.8 knitr_1.17 git2r_0.20.0
[13] stringr_1.2.0 digest_0.6.13 evaluate_0.10.1This R Markdown site was created with workflowr