Voom on null data - multiple examples
M Stephens
2016-10-21
Last updated: 2017-12-21
Code version: 6e42447d053260ae6798ad7a7f04532c41976c02
Introduction
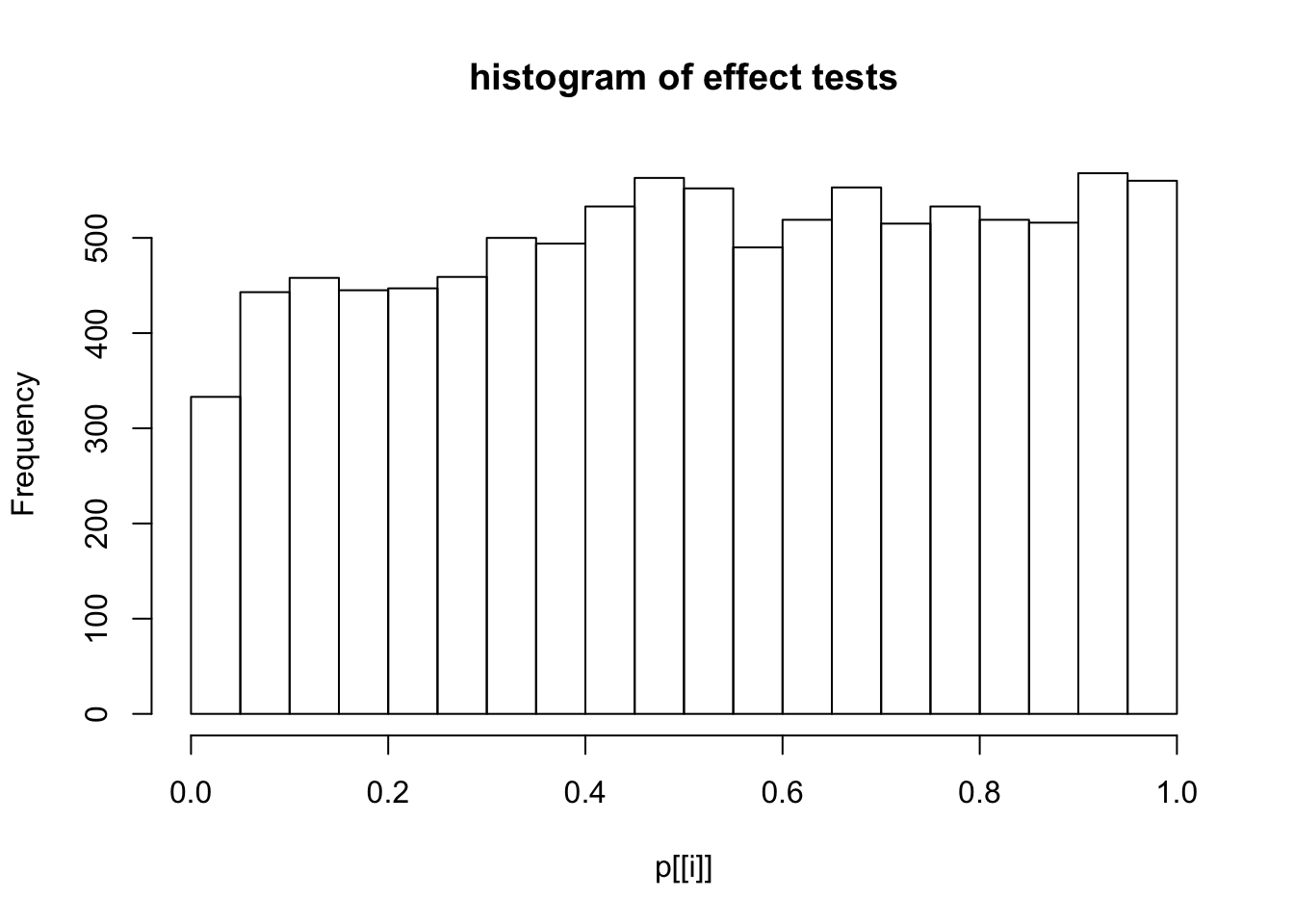
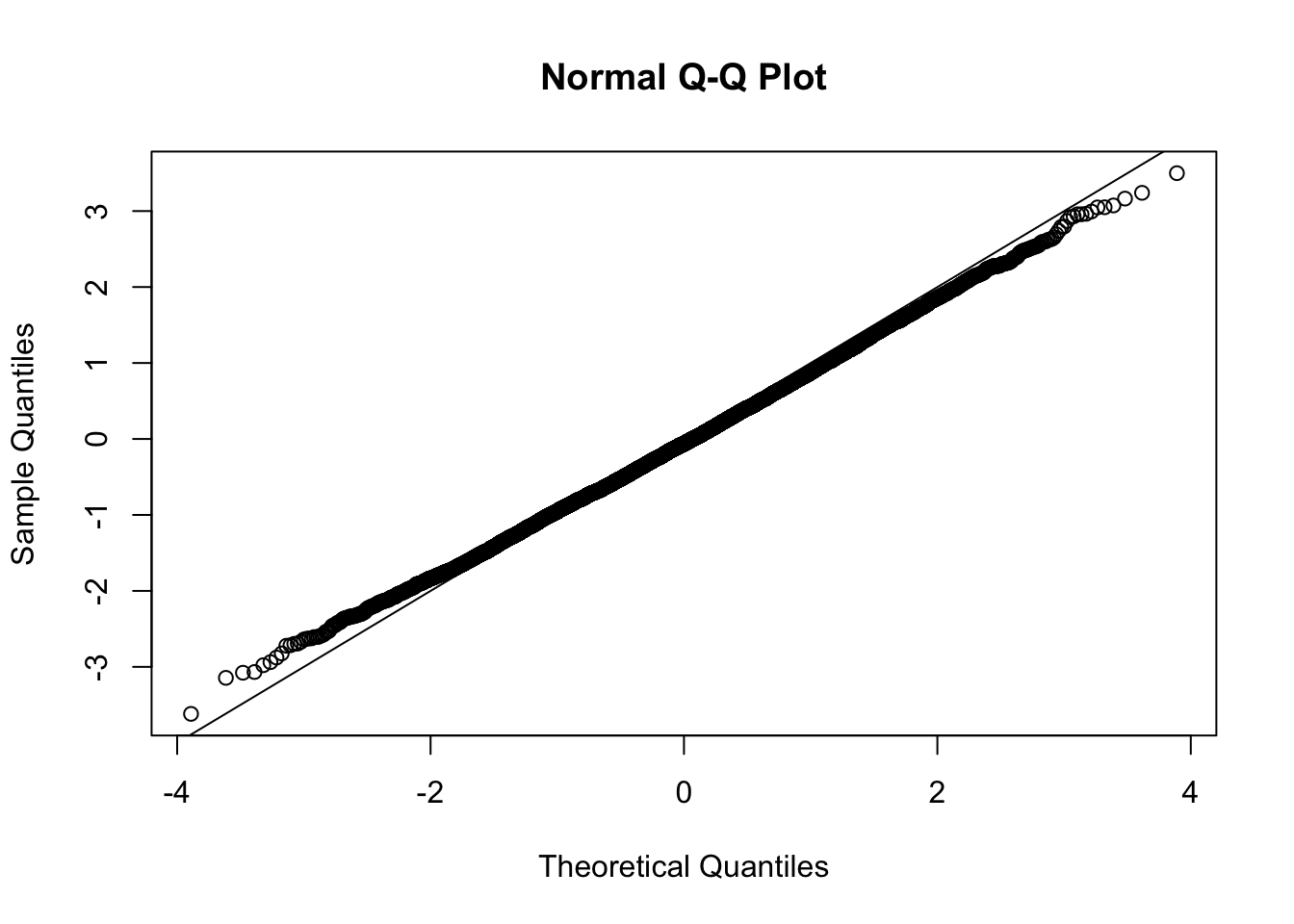
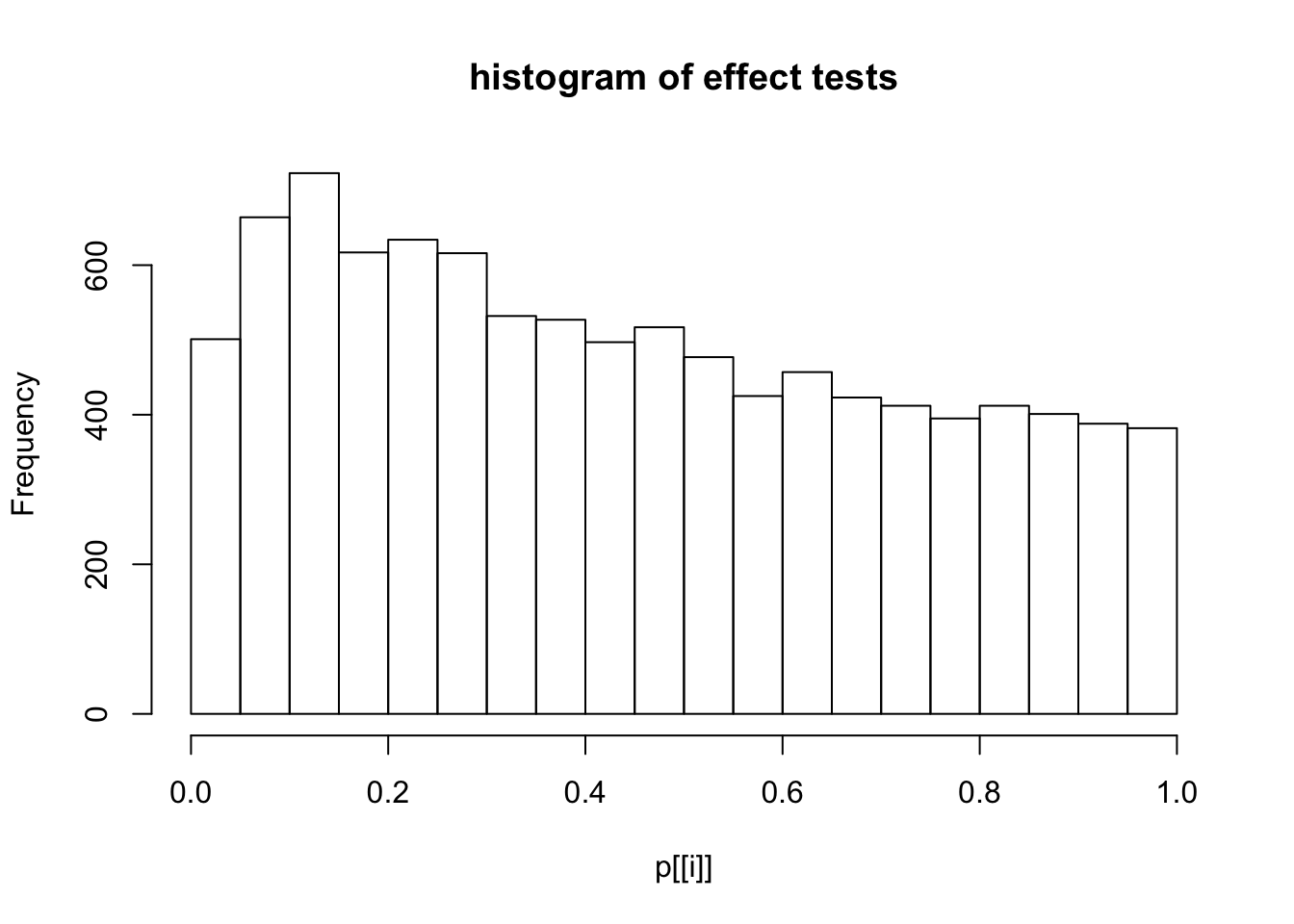
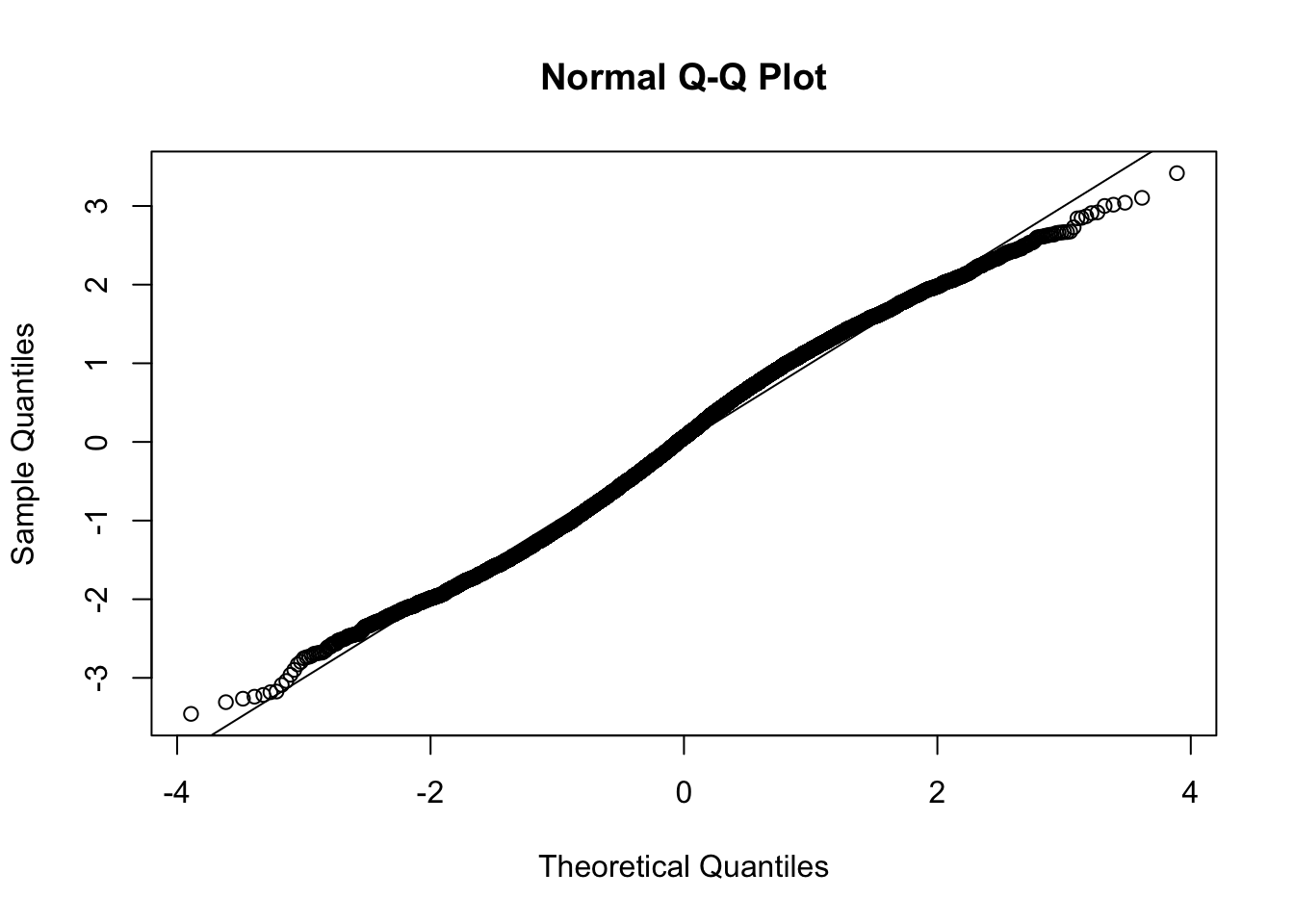
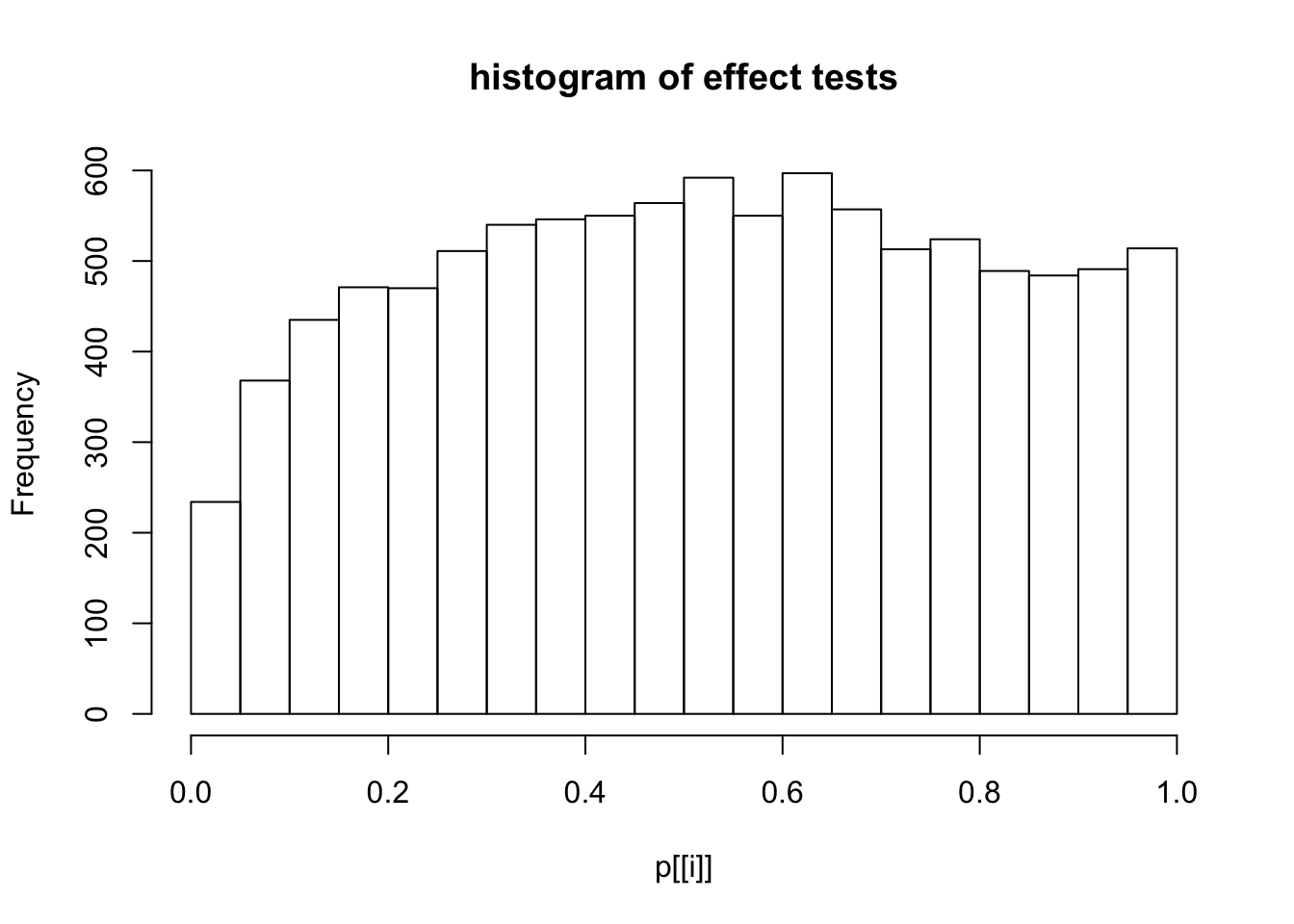
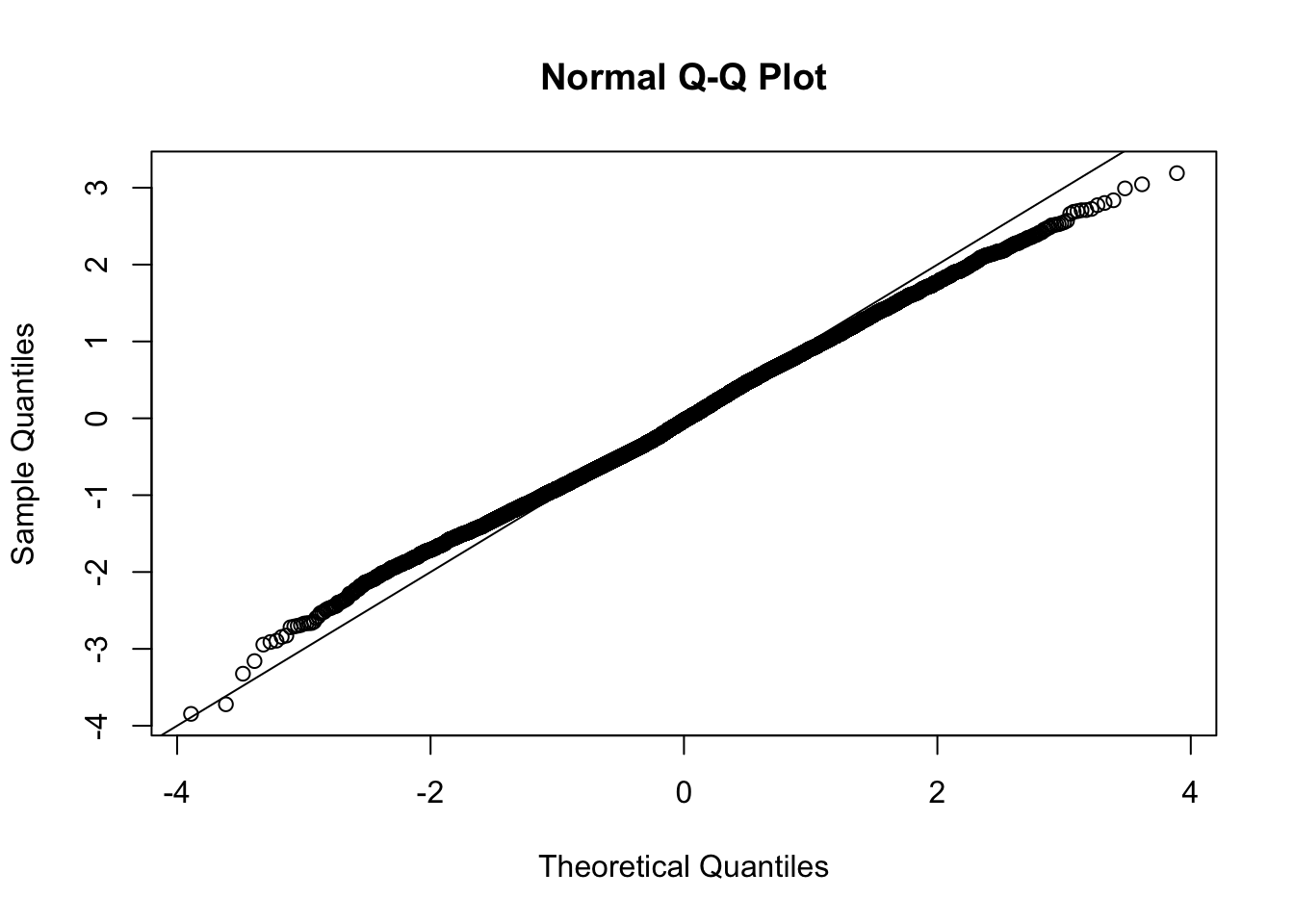
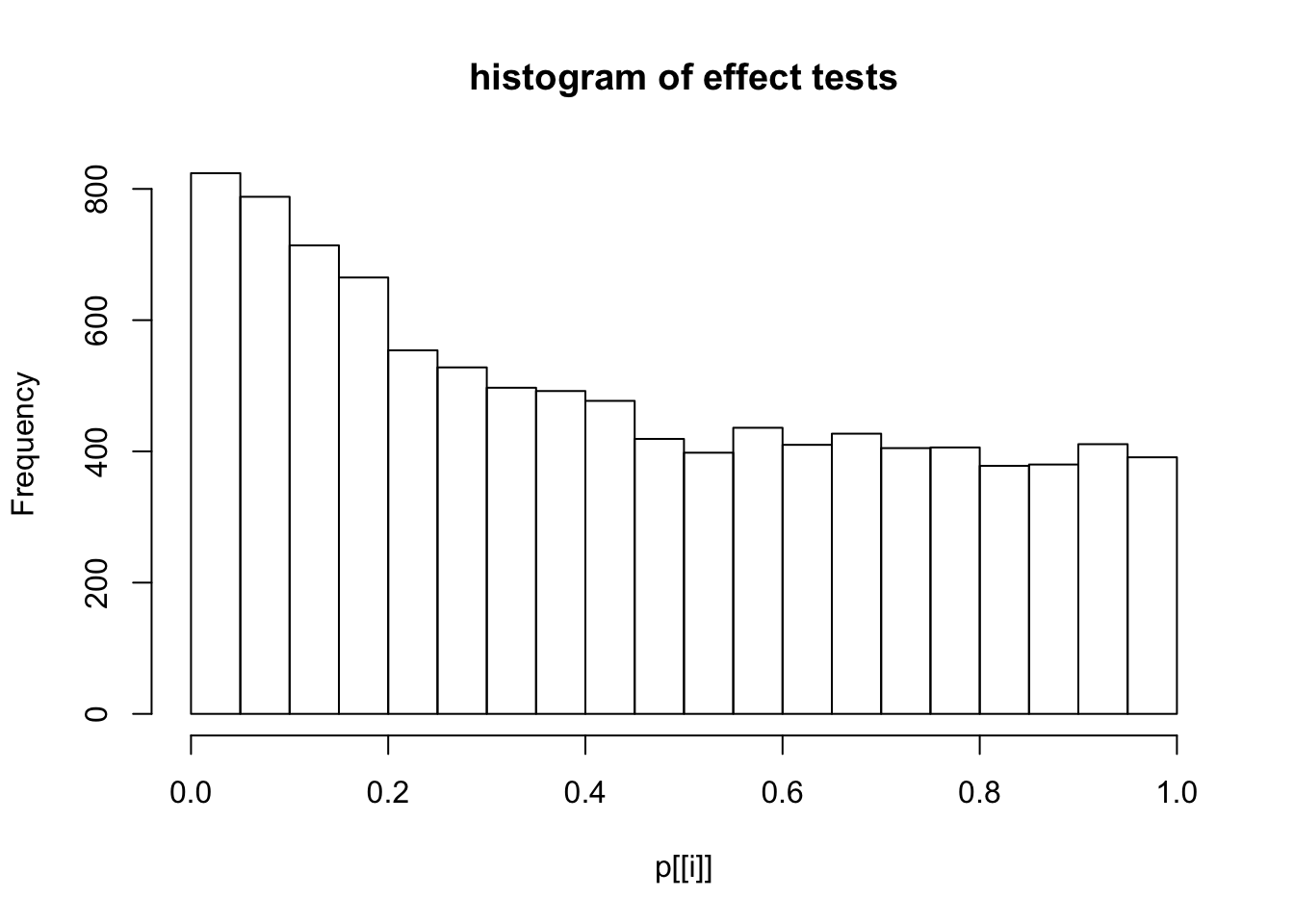
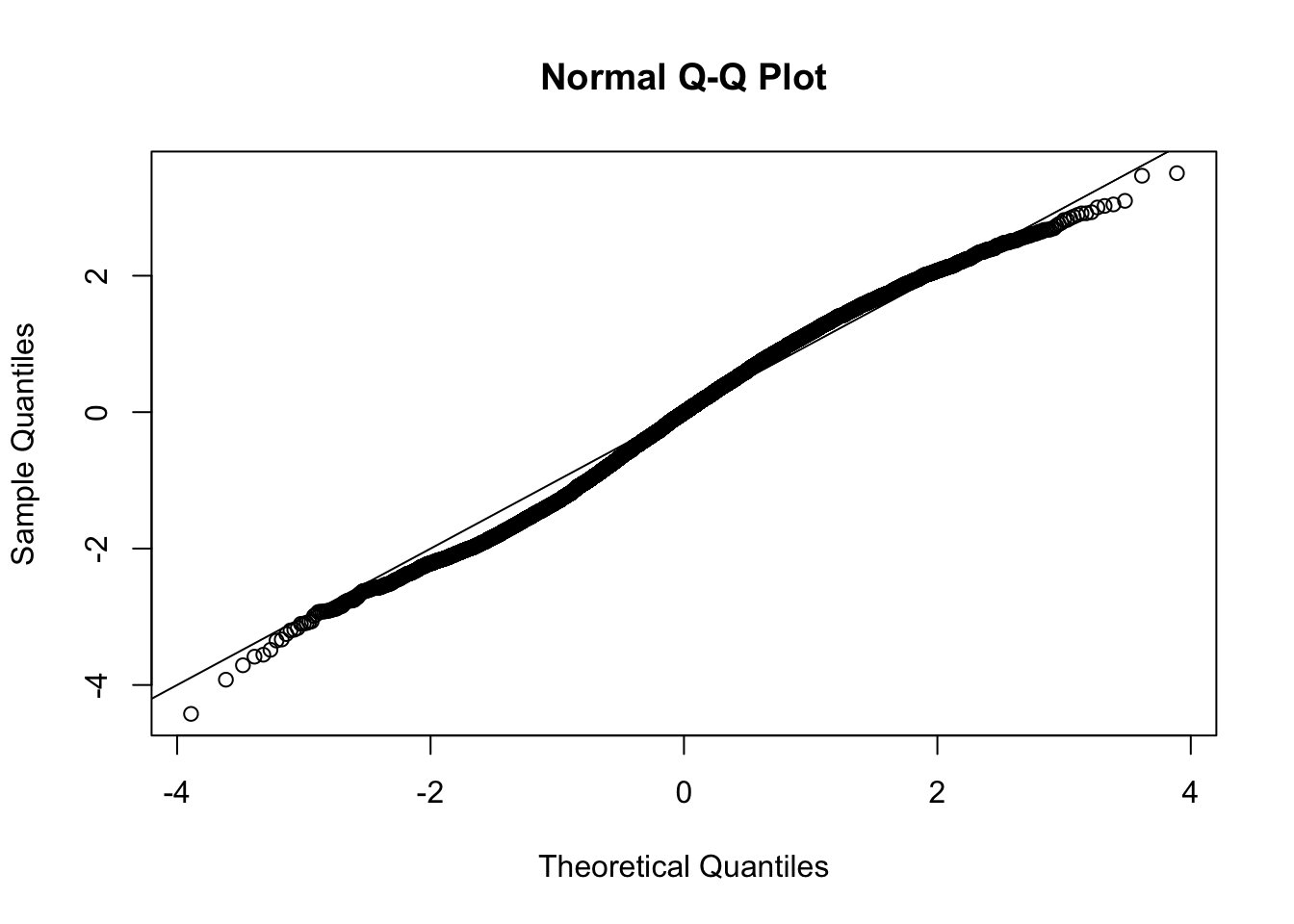
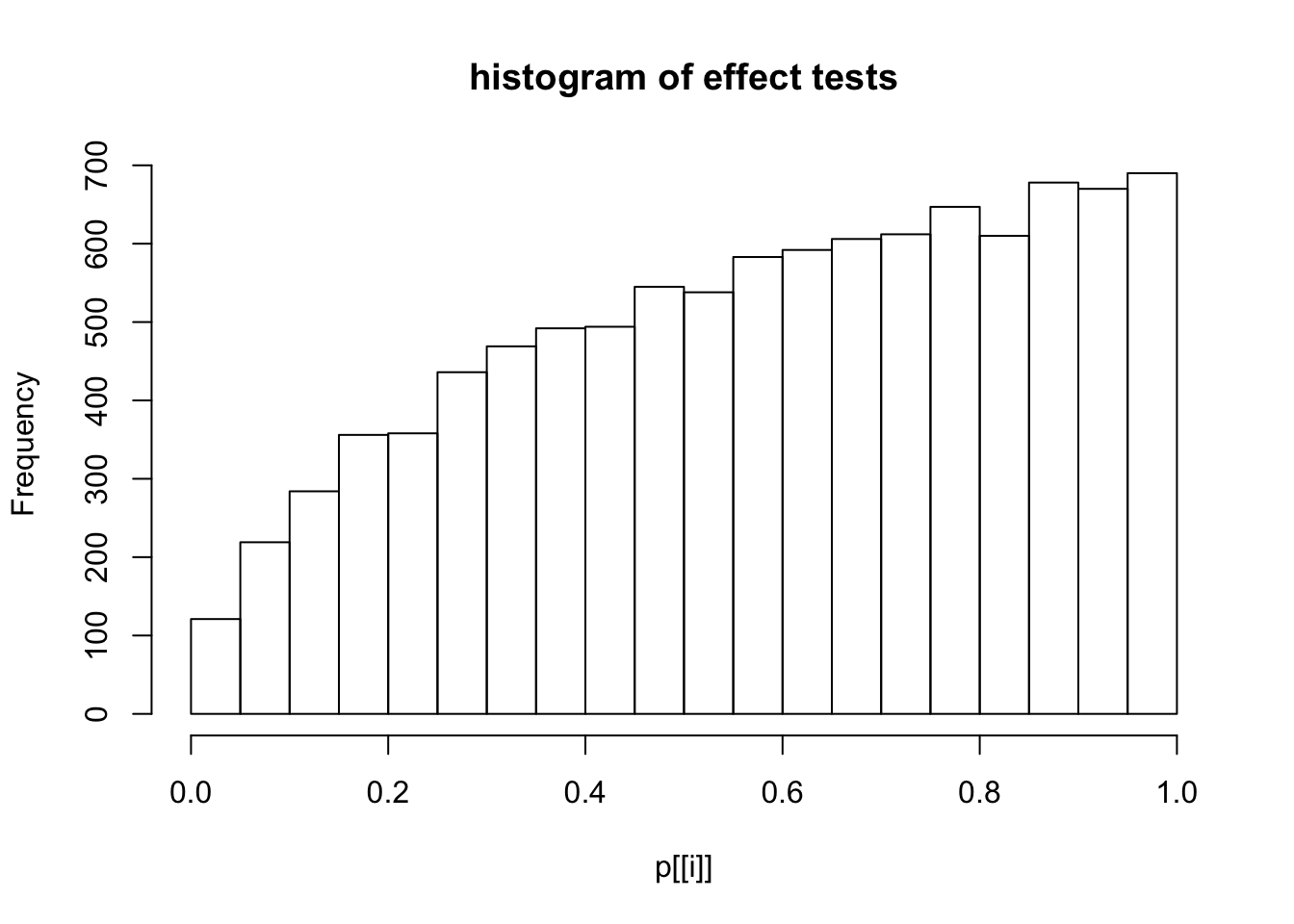
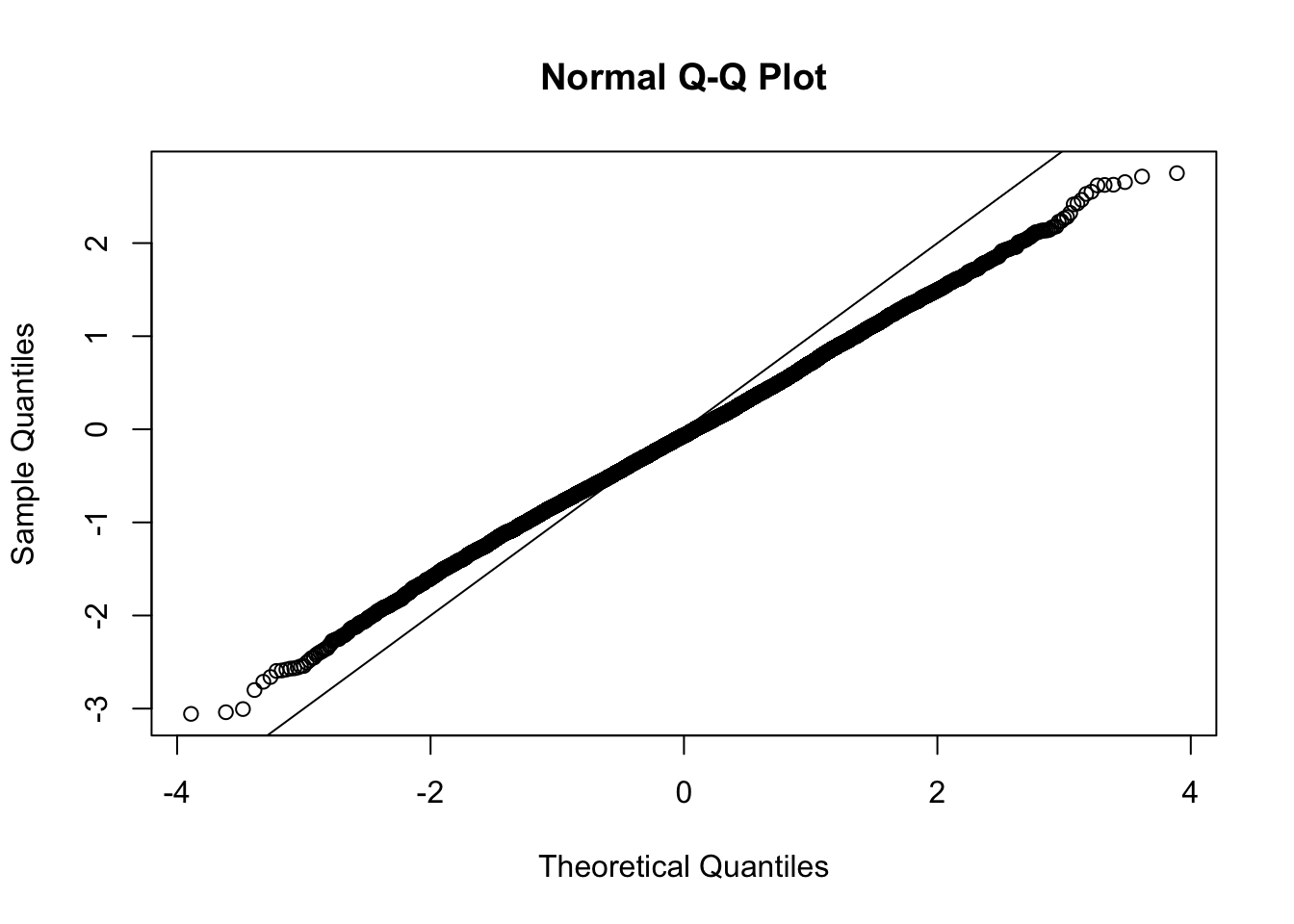
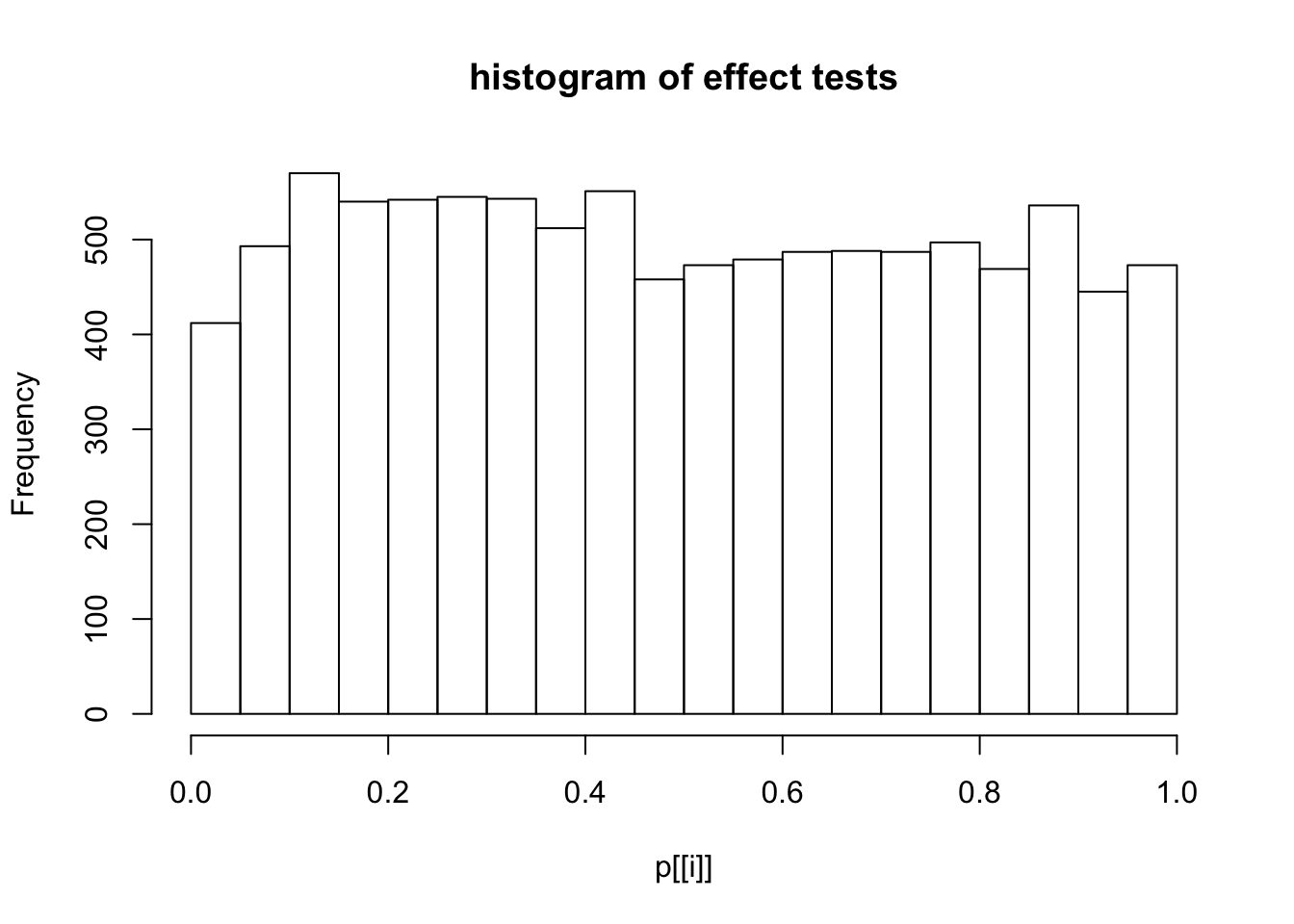
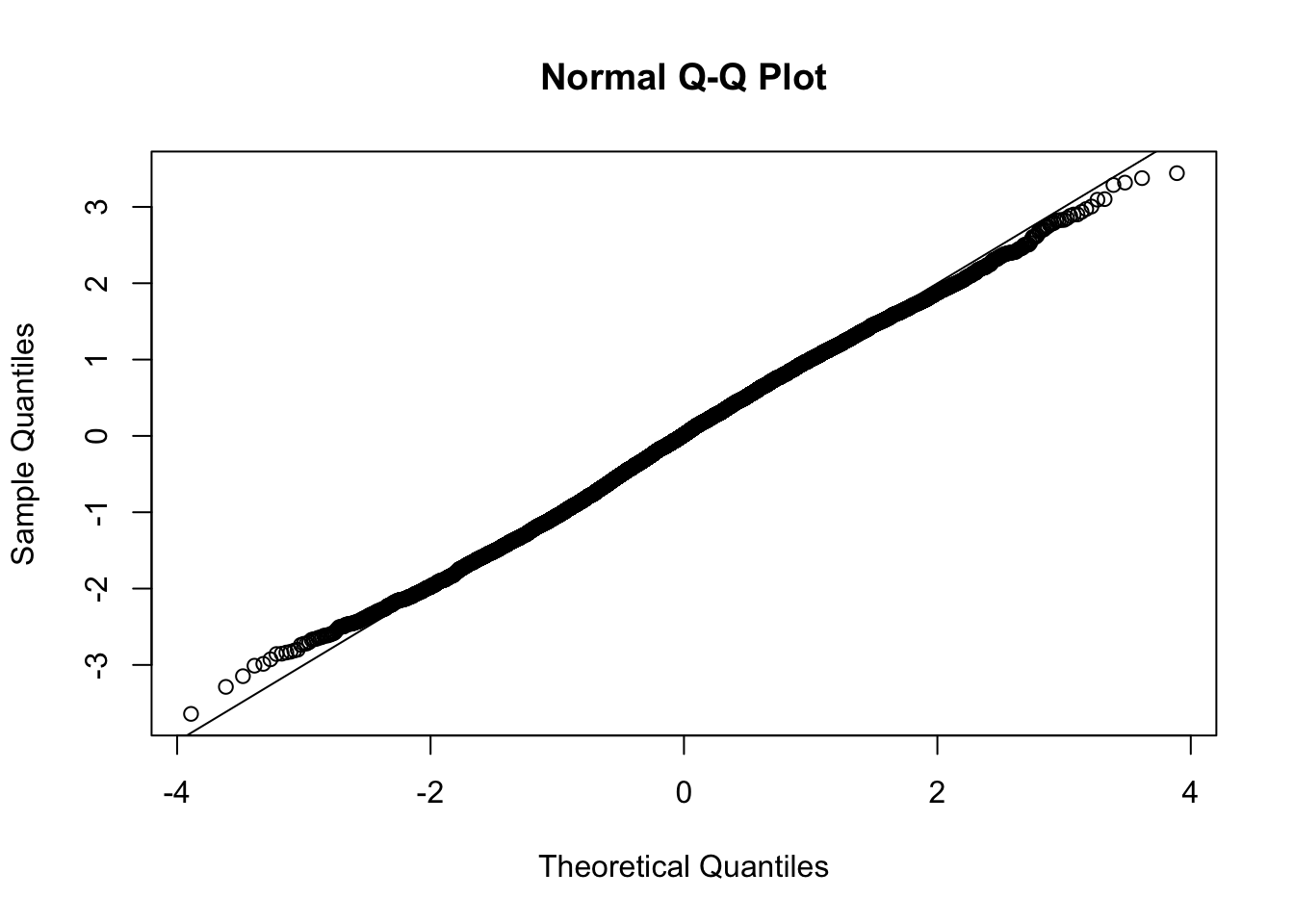
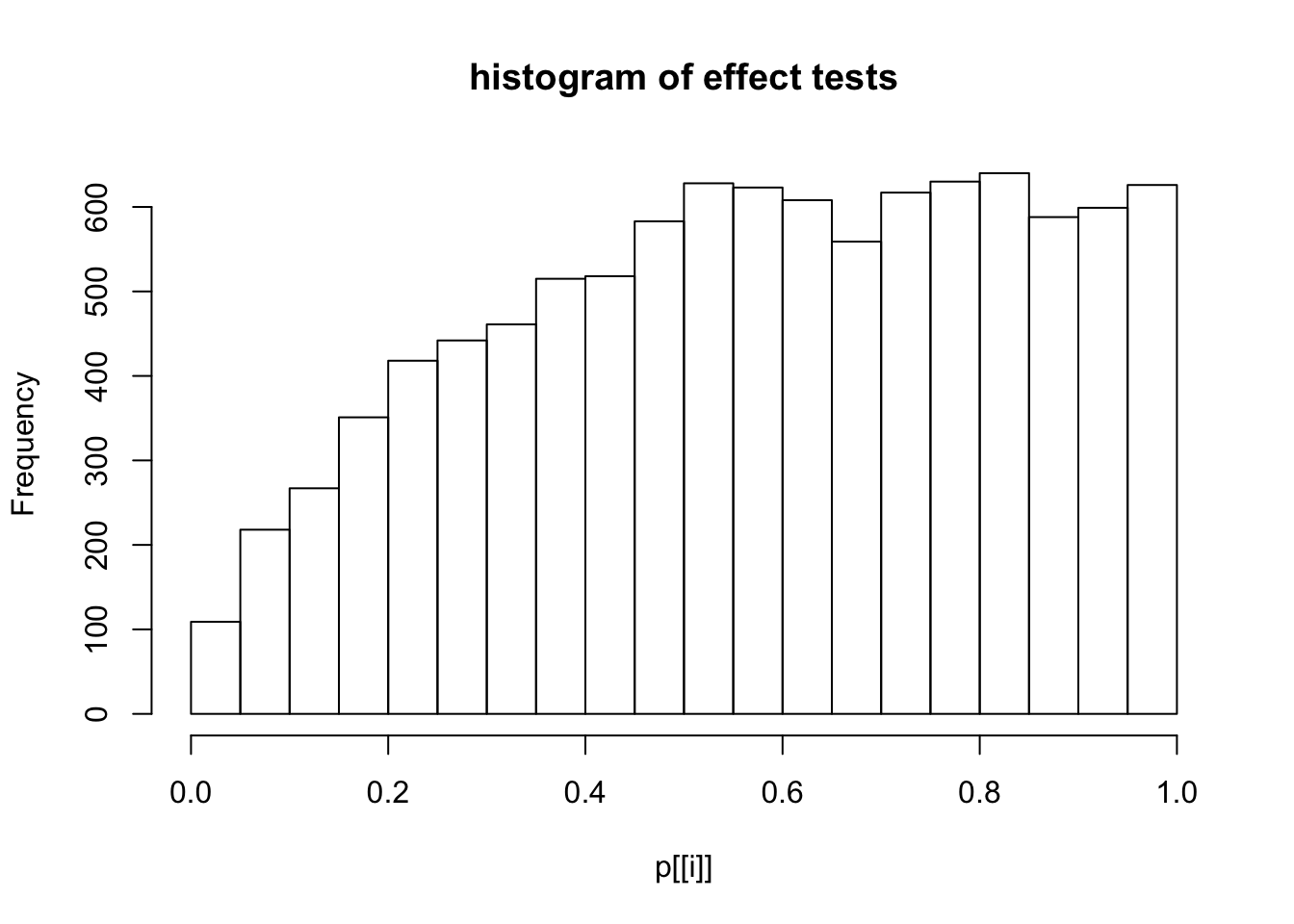
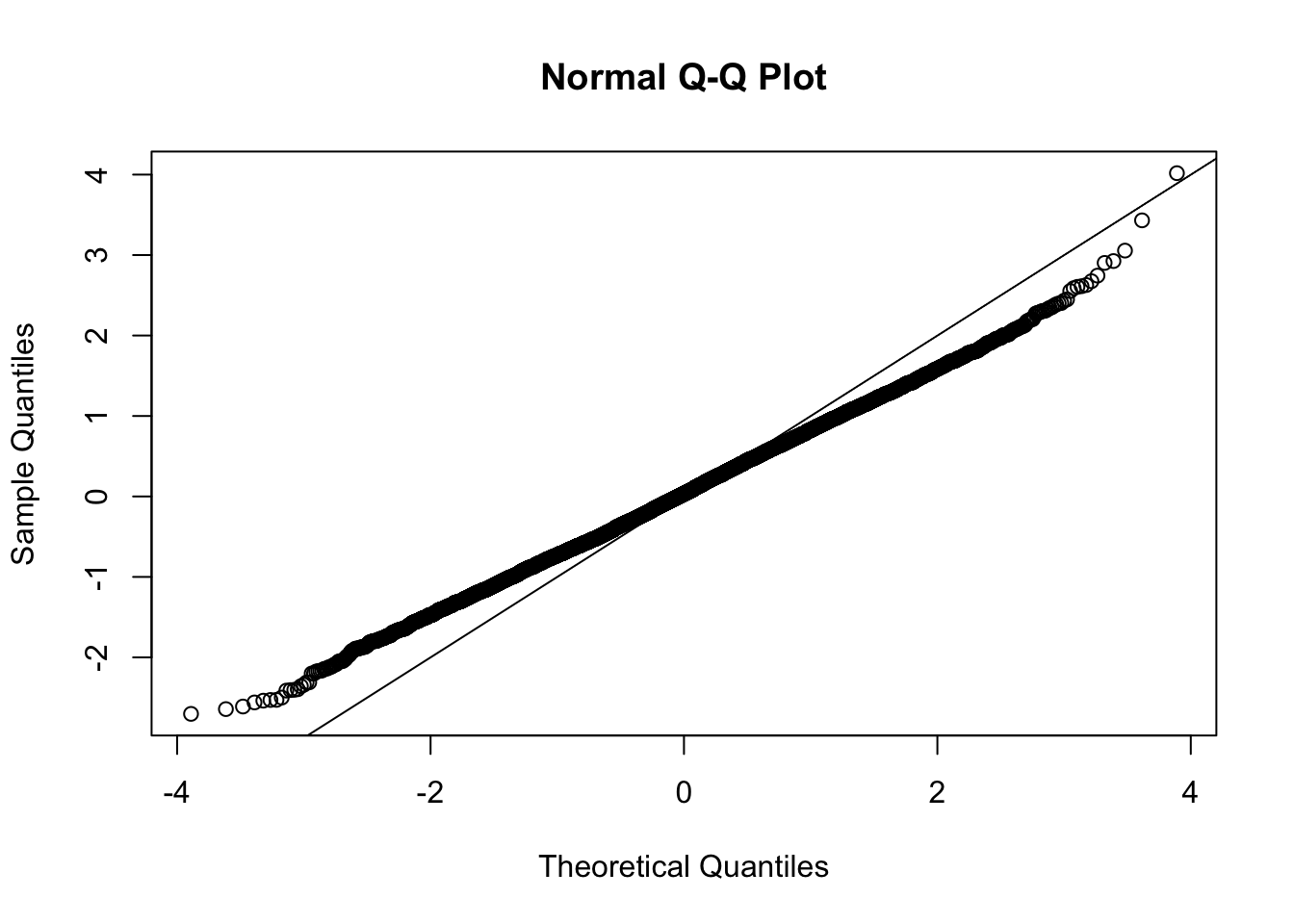
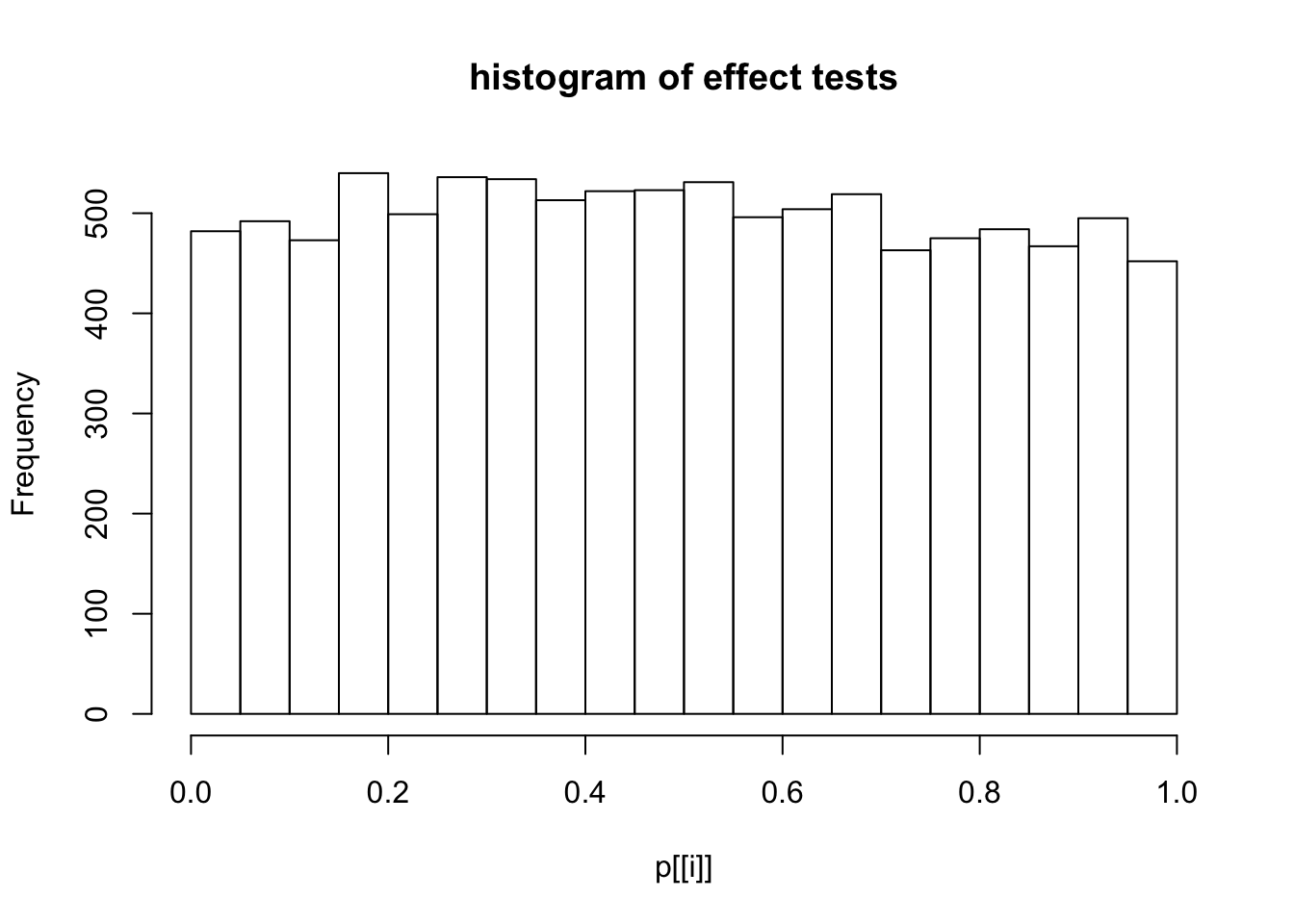
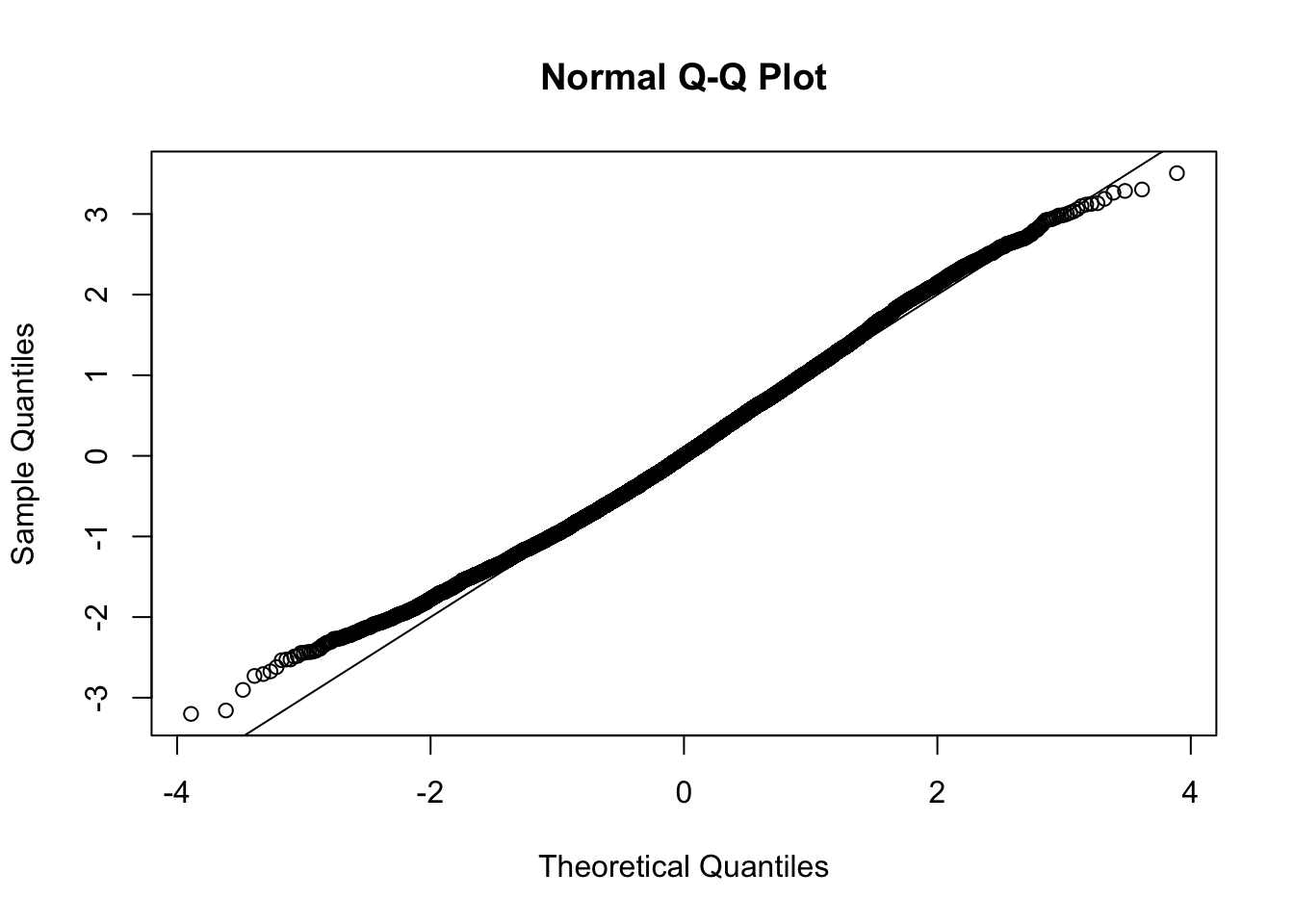
This document simply simulates some null data by randomly sampling two groups of 5 samples from some RNA-seq data (GTEx liver samples). We plot \(p\) value histograms and see the effects of inflation: some distributions are inflated near 0 and others are inflated near 1. However, when we look at the qqplots (here of the z scores, but should be same for p values) we see something that is interesting, although obvious in hindsight: the most extreme p values (z scores) are never “too extreme” (although they are sometimes not extreme enough). The inflation comes from the “not quite so extreme” p values and z scores. This makes sense: when you have positively correlated variables, the most extreme values will tend to be less extreme than when you have independent samples, because you have “effectively” fewer independent samples.
It seems likely this can be exploited to help avoid false positives under positive correlation.
Load in the gtex liver data
library(limma)
library(edgeR)
library(qvalue)
library(ashr)
r = read.csv("../data/Liver.csv")
r = r[,-(1:2)] # remove outliers
#extract top g genes from G by n matrix X of expression
top_genes_index=function(g,X){return(order(rowSums(X),decreasing =TRUE)[1:g])}
lcpm = function(r){R = colSums(r); t(log2(((t(r)+0.5)/(R+1))* 10^6))}
Y=lcpm(r)
subset = top_genes_index(10000,Y)
Y = Y[subset,]
r = r[subset,]Define voom transform (using code from Mengyin Lu)
voom_transform = function(counts, condition, W=NULL){
dgecounts = calcNormFactors(DGEList(counts=counts,group=condition))
#dgecounts = DGEList(counts=counts,group=condition)
if (is.null(W)){
design = model.matrix(~condition)
}else{
design = model.matrix(~condition+W)
}
v = voom(dgecounts,design,plot=FALSE)
lim = lmFit(v)
betahat.voom = lim$coefficients[,2]
sebetahat.voom = lim$stdev.unscaled[,2]*lim$sigma
df.voom = length(condition)-2-!is.null(W)
return(list(v=v,lim=lim,betahat=betahat.voom, sebetahat=sebetahat.voom, df=df.voom, v=v))
}Make 2 groups of size n, and repeat random sampling.
set.seed(101)
n = 5 # number in each group
p = list()
z = list()
tscore =list()
for(i in 1:10){
counts = r[,sample(1:ncol(r),2*n)]
condition = c(rep(0,n),rep(1,n))
r.voom = voom_transform(counts,condition)
r.ebayes = eBayes(r.voom$lim)
p[[i]] = r.ebayes$p.value[,2]
tscore[[i]] = r.ebayes$t[,2]
z[[i]] = sign(r.ebayes$t[,2]) * qnorm(p[[i]]/2)
hist(p[[i]],main="histogram of effect tests")
qqnorm(z[[i]])
abline(a=0,b=1,col=1)
}
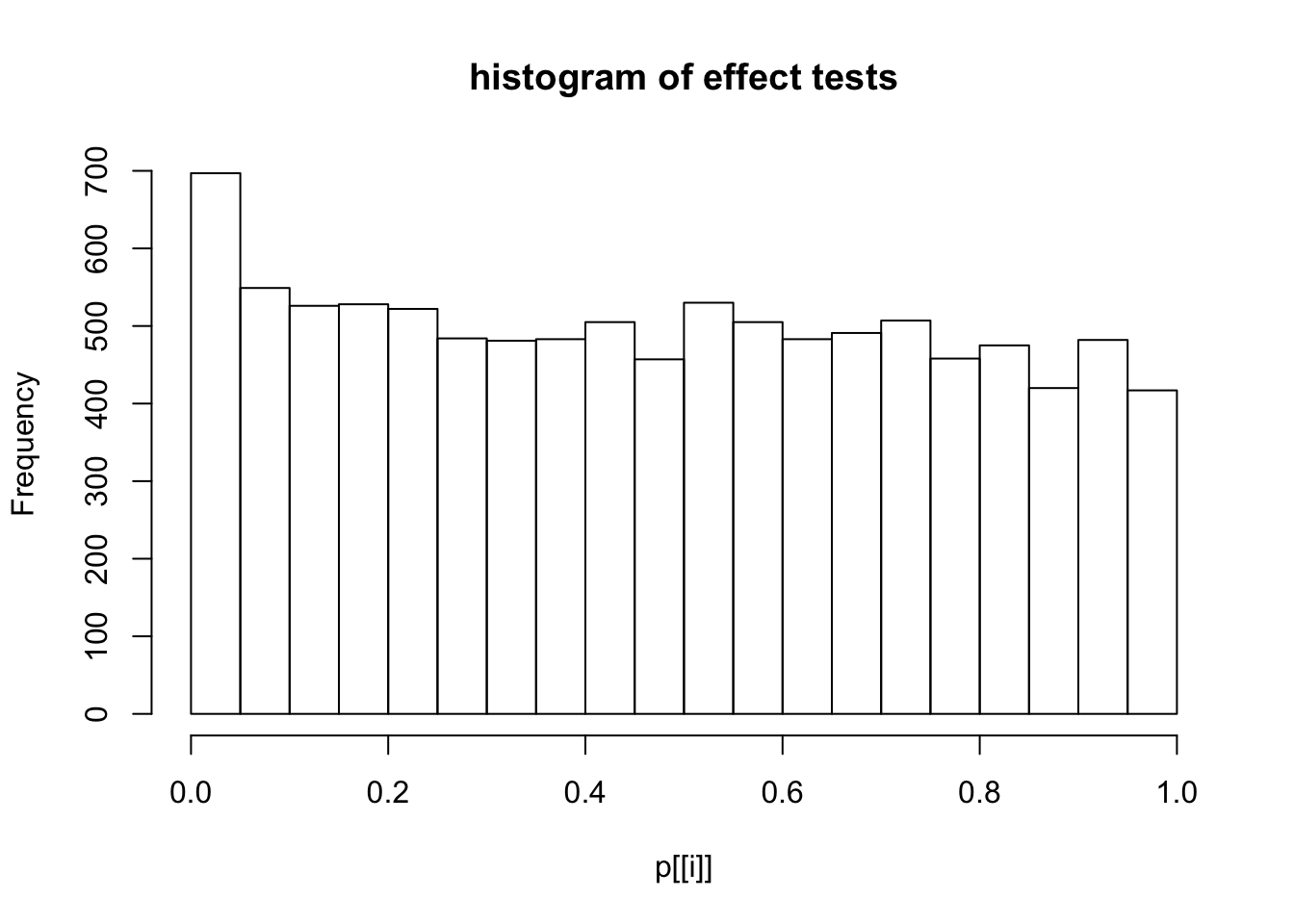
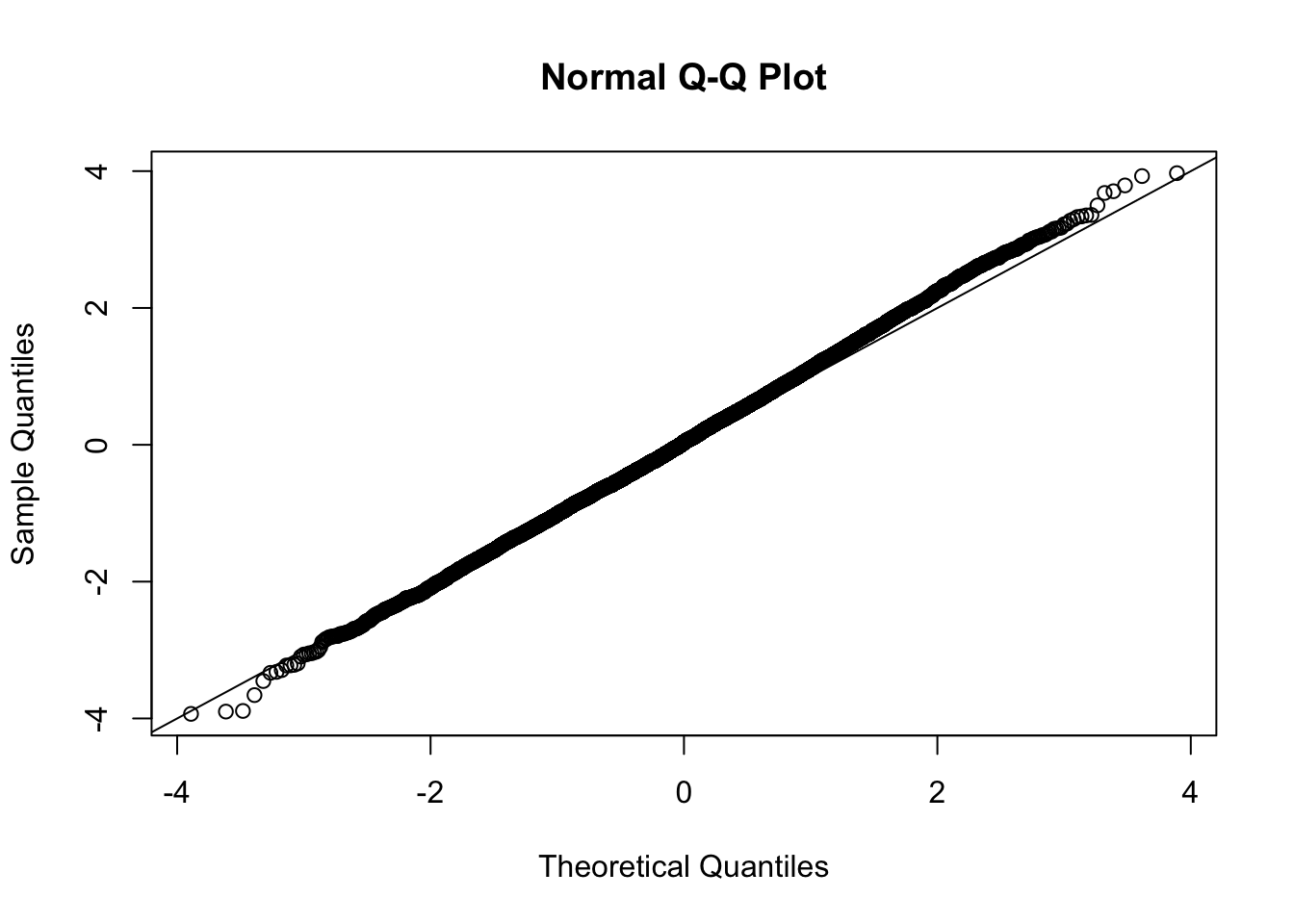
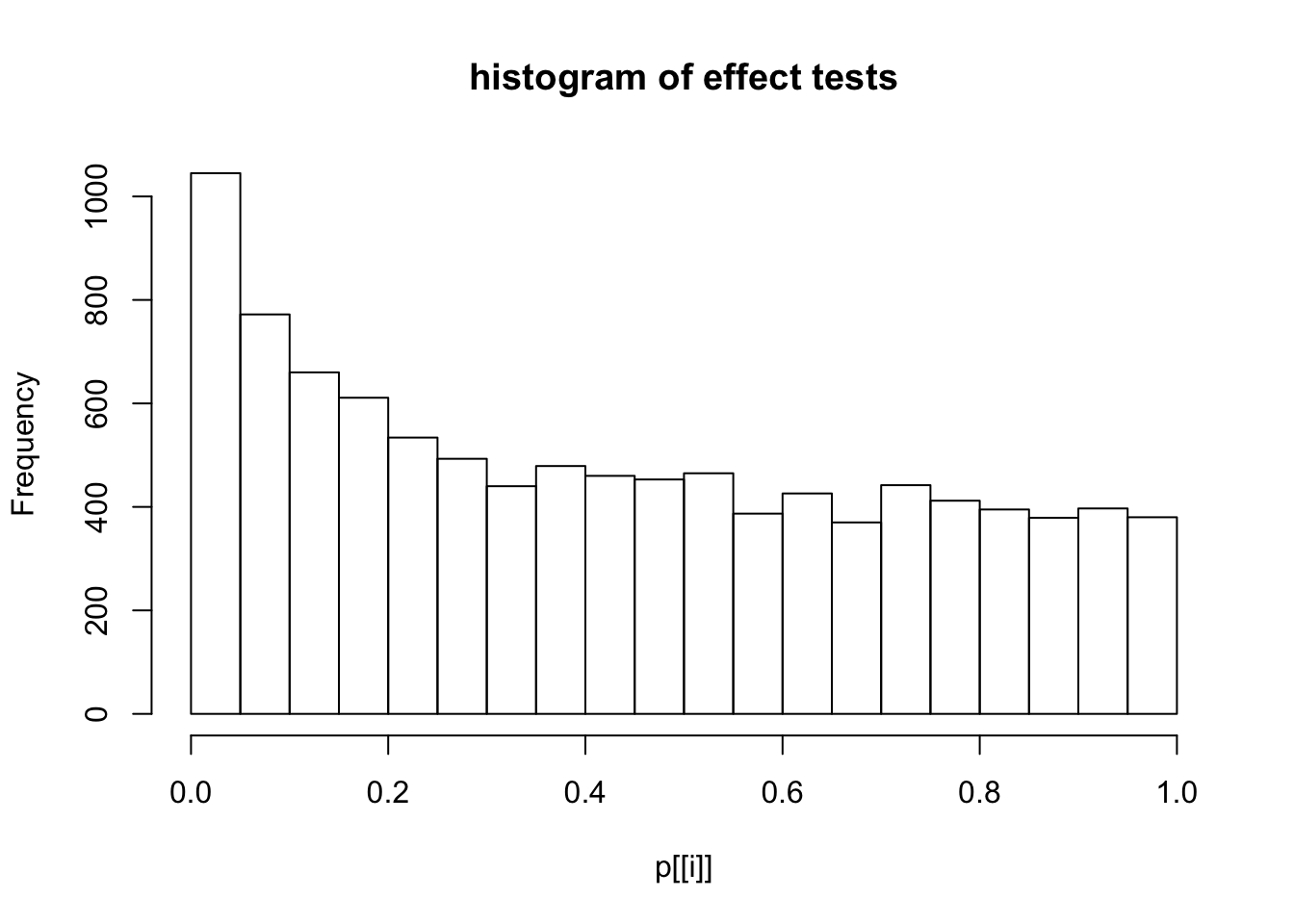
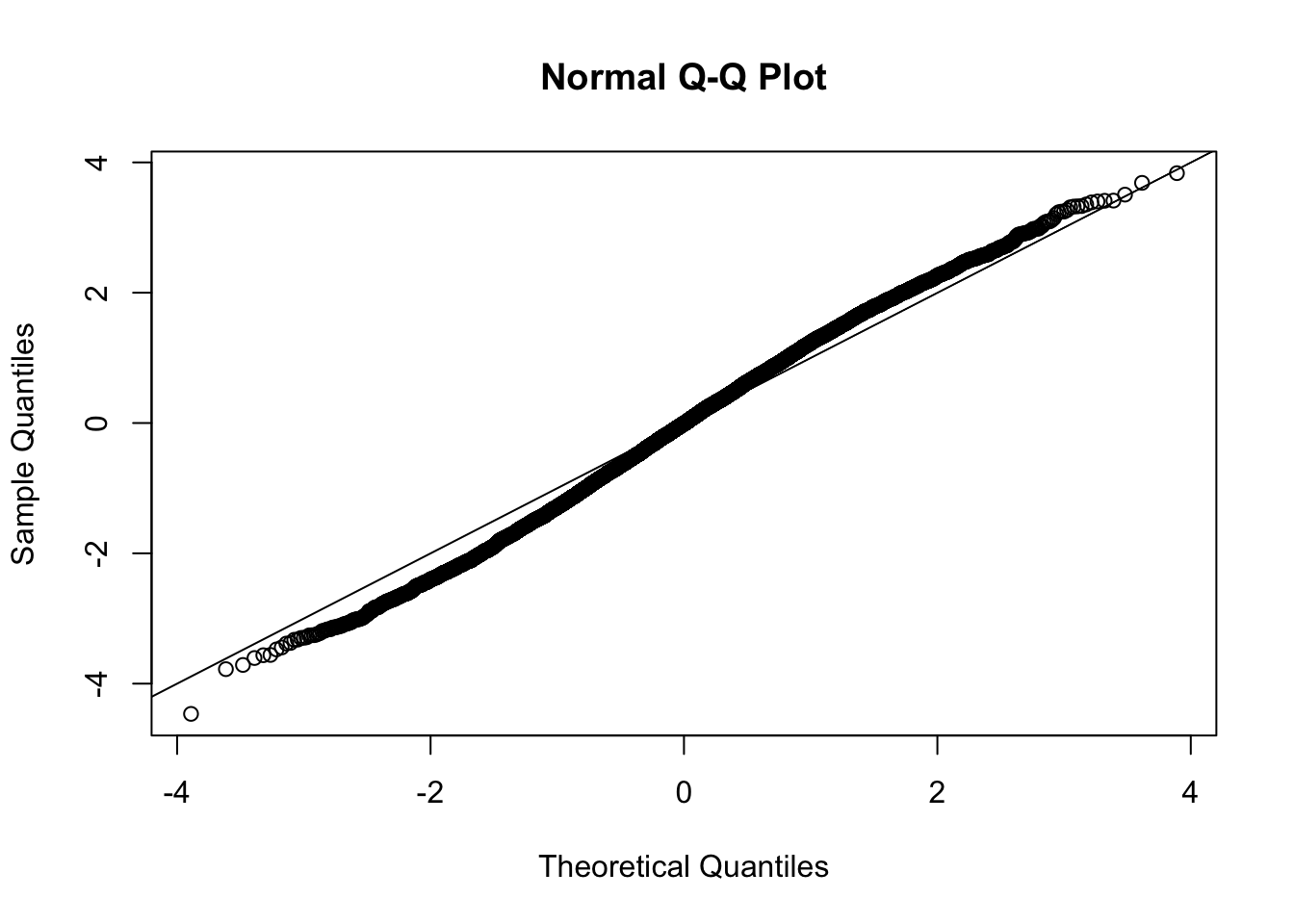
Session information
sessionInfo()R version 3.4.3 (2017-11-30)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS High Sierra 10.13.2
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.4/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.4/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ashr_2.2-2 qvalue_2.10.0 edgeR_3.20.2 limma_3.34.4
loaded via a namespace (and not attached):
[1] Rcpp_0.12.14 compiler_3.4.3 git2r_0.20.0
[4] plyr_1.8.4 iterators_1.0.9 tools_3.4.3
[7] digest_0.6.13 evaluate_0.10.1 tibble_1.3.4
[10] gtable_0.2.0 lattice_0.20-35 rlang_0.1.4
[13] Matrix_1.2-12 foreach_1.4.4 yaml_2.1.16
[16] parallel_3.4.3 stringr_1.2.0 knitr_1.17
[19] locfit_1.5-9.1 rprojroot_1.3-1 grid_3.4.3
[22] rmarkdown_1.8 ggplot2_2.2.1 reshape2_1.4.3
[25] magrittr_1.5 backports_1.1.2 scales_0.5.0
[28] codetools_0.2-15 htmltools_0.3.6 splines_3.4.3
[31] MASS_7.3-47 colorspace_1.3-2 stringi_1.1.6
[34] lazyeval_0.2.1 munsell_0.4.3 doParallel_1.0.11
[37] pscl_1.5.2 truncnorm_1.0-7 SQUAREM_2017.10-1This R Markdown site was created with workflowr